0.23.0 版本(2018 年 5 月 15 日)的新特性#
这是 0.22.0 的一个主要版本,包含多项 API 变更、弃用、新功能、增强和性能改进,以及大量的错误修复。我们建议所有用户升级到此版本。
主要亮点包括
警告
从 2019 年 1 月 1 日起,pandas 功能版本将仅支持 Python 3。更多信息请参阅 放弃 Python 2.7。
新功能#
JSON 读/写可往返,使用 orient='table'#
通过使用 orient='table' 参数,DataFrame 现在可以写入 JSON 并随后读回,同时保留元数据(参见 GH 18912 和 GH 9146)。此前,所有可用的 orient 值都无法保证保留 dtype 和索引名称等元数据。
In [1]: df = pd.DataFrame({'foo': [1, 2, 3, 4],
...: 'bar': ['a', 'b', 'c', 'd'],
...: 'baz': pd.date_range('2018-01-01', freq='d', periods=4),
...: 'qux': pd.Categorical(['a', 'b', 'c', 'c'])},
...: index=pd.Index(range(4), name='idx'))
...:
In [2]: df
Out[2]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [3]: df.dtypes
Out[3]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
In [4]: df.to_json('test.json', orient='table')
In [5]: new_df = pd.read_json('test.json', orient='table')
In [6]: new_df
Out[6]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [7]: new_df.dtypes
Out[7]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
请注意,往返格式不支持字符串 index,因为它在 write_json 中默认用于指示缺失的索引名称。
In [8]: df.index.name = 'index'
In [9]: df.to_json('test.json', orient='table')
In [10]: new_df = pd.read_json('test.json', orient='table')
In [11]: new_df
Out[11]:
foo bar baz qux
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [12]: new_df.dtypes
Out[12]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
方法 .assign() 接受依赖参数#
DataFrame.assign() 现在接受 Python 3.6 及更高版本的依赖关键字参数(另请参阅 PEP 468)。如果参数是可调用对象,则后续的关键字参数现在可以引用前面的参数。请参阅 此处文档 (GH 14207)
In [13]: df = pd.DataFrame({'A': [1, 2, 3]})
In [14]: df
Out[14]:
A
0 1
1 2
2 3
[3 rows x 1 columns]
In [15]: df.assign(B=df.A, C=lambda x: x['A'] + x['B'])
Out[15]:
A B C
0 1 1 2
1 2 2 4
2 3 3 6
[3 rows x 3 columns]
警告
当您使用 .assign() 更新现有列时,这可能会微妙地改变您代码的行为。以前,引用其他正在更新的变量的可调用对象会获取“旧”值。
旧行为
In [2]: df = pd.DataFrame({"A": [1, 2, 3]})
In [3]: df.assign(A=lambda df: df.A + 1, C=lambda df: df.A * -1)
Out[3]:
A C
0 2 -1
1 3 -2
2 4 -3
新行为
In [16]: df.assign(A=df.A + 1, C=lambda df: df.A * -1)
Out[16]:
A C
0 2 -2
1 3 -3
2 4 -4
[3 rows x 2 columns]
基于列和索引级别的组合进行合并#
传递给 DataFrame.merge() 作为 on、left_on 和 right_on 参数的字符串现在可以引用列名或索引级别名称。这使得 DataFrame 实例可以在不重置索引的情况下,基于索引级别和列的组合进行合并。请参阅 按列和级别合并 文档部分。(GH 14355)
In [17]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [18]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']},
....: index=left_index)
....:
In [19]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [20]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3'],
....: 'key2': ['K0', 'K0', 'K0', 'K1']},
....: index=right_index)
....:
In [21]: left.merge(right, on=['key1', 'key2'])
Out[21]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
[3 rows x 5 columns]
基于列和索引级别的组合进行排序#
传递给 DataFrame.sort_values() 作为 by 参数的字符串现在可以引用列名或索引级别名称。这使得 DataFrame 实例可以在不重置索引的情况下,基于索引级别和列的组合进行排序。请参阅 按索引和值排序 文档部分。(GH 14353)
# Build MultiIndex
In [22]: idx = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('a', 2),
....: ('b', 2), ('b', 1), ('b', 1)])
....:
In [23]: idx.names = ['first', 'second']
# Build DataFrame
In [24]: df_multi = pd.DataFrame({'A': np.arange(6, 0, -1)},
....: index=idx)
....:
In [25]: df_multi
Out[25]:
A
first second
a 1 6
2 5
2 4
b 2 3
1 2
1 1
[6 rows x 1 columns]
# Sort by 'second' (index) and 'A' (column)
In [26]: df_multi.sort_values(by=['second', 'A'])
Out[26]:
A
first second
b 1 1
1 2
a 1 6
b 2 3
a 2 4
2 5
[6 rows x 1 columns]
使用自定义类型扩展 pandas(实验性)#
pandas 现在支持将不一定是 1-D NumPy 数组的类数组对象存储为 DataFrame 中的列或 Series 中的值。这允许第三方库实现对 NumPy 类型的扩展,类似于 pandas 如何实现分类、带有时区的日期时间、周期和区间。
为了演示,我们将使用 cyberpandas,它提供了一个 IPArray 类型用于存储 IP 地址。
In [1]: from cyberpandas import IPArray
In [2]: values = IPArray([
...: 0,
...: 3232235777,
...: 42540766452641154071740215577757643572
...: ])
...:
...:
IPArray 不是一个普通的 1-D NumPy 数组,但由于它是一个 pandas ExtensionArray,它可以正确地存储在 pandas 的容器中。
In [3]: ser = pd.Series(values)
In [4]: ser
Out[4]:
0 0.0.0.0
1 192.168.1.1
2 2001:db8:85a3::8a2e:370:7334
dtype: ip
请注意,dtype 是 ip。底层数组的缺失值语义得到遵守
In [5]: ser.isna()
Out[5]:
0 True
1 False
2 False
dtype: bool
用于排除 GroupBy 中未观察类别的 observed 新关键字#
按类别分组会包含输出中未观察到的类别。当按多个类别列分组时,这意味着您会得到所有类别的笛卡尔积,包括没有观察值的组合,这可能导致大量的分组。我们添加了一个关键字 observed 来控制此行为,为了向后兼容,它默认为 observed=False。(GH 14942、GH 8138、GH 15217、GH 17594、GH 8669、GH 20583、GH 20902)
In [27]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [28]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [29]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [30]: df['C'] = ['foo', 'bar'] * 2
In [31]: df
Out[31]:
A B values C
0 a c 1 foo
1 a d 2 bar
2 b c 3 foo
3 b d 4 bar
[4 rows x 4 columns]
显示所有值,旧行为
In [32]: df.groupby(['A', 'B', 'C'], observed=False).count()
Out[32]:
values
A B C
a c bar 0
foo 1
d bar 1
foo 0
y bar 0
... ...
z c foo 0
d bar 0
foo 0
y bar 0
foo 0
[18 rows x 1 columns]
仅显示已观察到的值
In [33]: df.groupby(['A', 'B', 'C'], observed=True).count()
Out[33]:
values
A B C
a c foo 1
d bar 1
b c foo 1
d bar 1
[4 rows x 1 columns]
对于透视操作,此行为已经由 dropna 关键字控制
In [34]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [35]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [36]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [37]: df
Out[37]:
A B values
0 a c 1
1 a d 2
2 b c 3
3 b d 4
[4 rows x 3 columns]
In [1]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=True)
Out[1]:
values
A B
a c 1.0
d 2.0
b c 3.0
d 4.0
In [2]: pd.pivot_table(df, values='values', index=['A', 'B'], dropna=False)
Out[2]:
values
A B
a c 1.0
d 2.0
y NaN
b c 3.0
d 4.0
y NaN
z c NaN
d NaN
y NaN
Rolling/Expanding.apply() 接受 raw=False 以将 Series 传递给函数#
Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply() 和 DataFrame.expanding().apply() 增加了 raw=None 参数。这类似于 DataFame.apply()。如果此参数为 True,则允许将 np.ndarray 发送到应用函数。如果为 False,则会传递 Series。默认值为 None,这保留了向后兼容性,因此它将默认为 True,发送 np.ndarray。在未来的版本中,默认值将更改为 False,发送 Series。(GH 5071、GH 20584)
In [38]: s = pd.Series(np.arange(5), np.arange(5) + 1)
In [39]: s
Out[39]:
1 0
2 1
3 2
4 3
5 4
Length: 5, dtype: int64
传递一个 Series
In [40]: s.rolling(2, min_periods=1).apply(lambda x: x.iloc[-1], raw=False)
Out[40]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
模拟传递 ndarray 的原始行为
In [41]: s.rolling(2, min_periods=1).apply(lambda x: x[-1], raw=True)
Out[41]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
DataFrame.interpolate 增加了 limit_area kwarg#
DataFrame.interpolate() 增加了一个 limit_area 参数,以进一步控制替换哪些 NaN 值。使用 limit_area='inside' 仅填充被有效值包围的 NaNs,或使用 limit_area='outside' 仅填充现有有效值外部的 NaN 值,同时保留内部的。 (GH 16284) 更多信息请参阅 完整文档。
In [42]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [43]: ser
Out[43]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
双向填充一个连续的内部值
In [44]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[44]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
向后填充所有连续的外部值
In [45]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[45]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
双向填充所有连续的外部值
In [46]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[46]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
Length: 9, dtype: float64
函数 get_dummies 现在支持 dtype 参数#
get_dummies() 现在接受一个 dtype 参数,该参数指定新列的 dtype。默认值仍为 uint8。(GH 18330)
In [47]: df = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6]})
In [48]: pd.get_dummies(df, columns=['c']).dtypes
Out[48]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
In [49]: pd.get_dummies(df, columns=['c'], dtype=bool).dtypes
Out[49]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
Timedelta 模运算方法#
mod (%) 和 divmod 运算现在在 Timedelta 对象上定义,当与类 timedelta 或数值参数操作时。请参阅 此处文档。(GH 19365)
In [50]: td = pd.Timedelta(hours=37)
In [51]: td % pd.Timedelta(minutes=45)
Out[51]: Timedelta('0 days 00:15:00')
当存在 NaN 时,方法 .rank() 处理 inf 值#
在以前的版本中,.rank() 会将 inf 元素分配为 NaN 作为其排名。现在排名计算正确。(GH 6945)
In [52]: s = pd.Series([-np.inf, 0, 1, np.nan, np.inf])
In [53]: s
Out[53]:
0 -inf
1 0.0
2 1.0
3 NaN
4 inf
Length: 5, dtype: float64
旧行为
In [11]: s.rank()
Out[11]:
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
当前行为
In [54]: s.rank()
Out[54]:
0 1.0
1 2.0
2 3.0
3 NaN
4 4.0
Length: 5, dtype: float64
此外,以前如果你将 inf 或 -inf 值与 NaN 值一起排名,在使用“top”或“bottom”参数时,计算不会区分 NaN 和无穷大。
In [55]: s = pd.Series([np.nan, np.nan, -np.inf, -np.inf])
In [56]: s
Out[56]:
0 NaN
1 NaN
2 -inf
3 -inf
Length: 4, dtype: float64
旧行为
In [15]: s.rank(na_option='top')
Out[15]:
0 2.5
1 2.5
2 2.5
3 2.5
dtype: float64
当前行为
In [57]: s.rank(na_option='top')
Out[57]:
0 1.5
1 1.5
2 3.5
3 3.5
Length: 4, dtype: float64
这些错误已修复
DataFrame.rank()和Series.rank()中的错误,当method='dense'和pct=True时,百分位排名未与不同观察值数量一起使用 (GH 15630)Series.rank()和DataFrame.rank()中的错误,当存在NaN时,ascending='False'未能返回正确的无穷大排名 (GH 19538)DataFrameGroupBy.rank()中的错误,当同时存在无穷大和NaN时,排名不正确 (GH 20561)
Series.str.cat 增加了 join kwarg#
以前,Series.str.cat() 在连接之前没有——与大多数 pandas 功能不同——根据索引对 Series 进行对齐(参见 GH 18657)。该方法现在增加了一个关键字 join 来控制对齐方式,请参阅下面的示例和 此处。
在 v.0.23 中,join 将默认为 None(表示不进行对齐),但在未来的 pandas 版本中,此默认值将更改为 'left'。
In [58]: s = pd.Series(['a', 'b', 'c', 'd'])
In [59]: t = pd.Series(['b', 'd', 'e', 'c'], index=[1, 3, 4, 2])
In [60]: s.str.cat(t)
Out[60]:
0 NaN
1 bb
2 cc
3 dd
Length: 4, dtype: object
In [61]: s.str.cat(t, join='left', na_rep='-')
Out[61]:
0 a-
1 bb
2 cc
3 dd
Length: 4, dtype: object
此外,Series.str.cat() 现在也适用于 CategoricalIndex(以前会引发 ValueError;参见 GH 20842)。
DataFrame.astype 执行按列转换为 Categorical#
DataFrame.astype() 现在可以通过提供字符串 'category' 或 CategoricalDtype 来执行按列转换为 Categorical。以前,尝试这样做会引发 NotImplementedError。有关更多详细信息和示例,请参阅文档的 对象创建 部分。(GH 12860、GH 18099)
提供字符串 'category' 执行按列转换,只有出现在给定列中的标签被设置为类别
In [62]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [63]: df = df.astype('category')
In [64]: df['A'].dtype
Out[64]: CategoricalDtype(categories=['a', 'b', 'c'], ordered=False, categories_dtype=object)
In [65]: df['B'].dtype
Out[65]: CategoricalDtype(categories=['b', 'c', 'd'], ordered=False, categories_dtype=object)
提供 CategoricalDtype 将使每列中的类别与提供的 dtype 保持一致
In [66]: from pandas.api.types import CategoricalDtype
In [67]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [68]: cdt = CategoricalDtype(categories=list('abcd'), ordered=True)
In [69]: df = df.astype(cdt)
In [70]: df['A'].dtype
Out[70]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
In [71]: df['B'].dtype
Out[71]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True, categories_dtype=object)
其他增强#
一元运算符
+现在允许用于Series和DataFrame作为数值运算符 (GH 16073)更好地支持
to_excel()与xlsxwriter引擎的输出。(GH 16149)pandas.tseries.frequencies.to_offset()现在接受前导的“+”号,例如“+1h”。(GH 18171)MultiIndex.unique()现在支持level=参数,以从特定索引级别获取唯一值(GH 17896)pandas.io.formats.style.Styler现在有一个hide_index()方法来确定索引是否在输出中渲染(GH 14194)pandas.io.formats.style.Styler现在有一个hide_columns()方法来确定列是否在输出中隐藏(GH 14194)改进了在
to_datetime()中当unit=传入不可转换值时引发的ValueError的措辞。(GH 14350)Series.fillna()现在接受 Series 或字典作为分类 dtype 的value。(GH 17033)pandas.read_clipboard()已更新为使用 qtpy,并回退到 PyQt5,然后是 PyQt4,增加了与 Python3 和多个 python-qt 绑定的兼容性。(GH 17722)改进了在
read_csv()中当usecols参数无法匹配所有列时引发的ValueError的措辞。(GH 17301)DataFrame.corrwith()现在在传递 Series 时会默默地删除非数值列。在此之前会引发异常。(GH 18570)IntervalIndex现在支持时区感知Interval对象(GH 18537、GH 18538)Series()/DataFrame()选项卡补全现在也会返回MultiIndex()第一级中的标识符。(GH 16326)read_excel()增加了nrows参数(GH 16645)对于子类化的
DataFrames,DataFrame.append()现在在更多情况下可以保留调用 dataframe 列的类型(例如,如果两者都是CategoricalIndex)(GH 18359)DataFrame.to_json()和Series.to_json()现在接受index参数,允许用户从 JSON 输出中排除索引(GH 17394)IntervalIndex.to_tuples()增加了na_tuple参数,用于控制 NA 是作为 NA 的元组返回,还是 NA 本身返回(GH 18756)Categorical.rename_categories、CategoricalIndex.rename_categories和Series.cat.rename_categories现在可以接受可调用对象作为其参数(GH 18862)Interval和IntervalIndex增加了length属性(GH 18789)Resampler对象现在具有功能正常的Resampler.pipe方法。以前,对pipe的调用会被重定向到mean方法。(GH 17905)is_scalar()现在对DateOffset对象返回True。(GH 18943)DataFrame.pivot()现在接受一个列表作为values=kwarg(GH 17160)。添加了
pandas.api.extensions.register_dataframe_accessor()、pandas.api.extensions.register_series_accessor()和pandas.api.extensions.register_index_accessor(),这些访问器允许 pandas 下游库注册自定义访问器,如 pandas 对象上的.cat。更多信息请参阅 注册自定义访问器(GH 14781)。IntervalIndex.astype现在在传入IntervalDtype时支持子类型之间的转换(GH 19197)IntervalIndex及其相关的构造方法(from_arrays、from_breaks、from_tuples)增加了dtype参数(GH 19262)添加了
SeriesGroupBy.is_monotonic_increasing()和SeriesGroupBy.is_monotonic_decreasing()(GH 17015)对于子类化的
DataFrames,DataFrame.apply()在将数据传递给应用函数时,现在将保留Series子类(如果已定义)(GH 19822)DataFrame.from_dict()现在接受columns参数,当使用orient='index'时,该参数可用于指定列名。(GH 18529)添加了选项
display.html.use_mathjax,以便在Jupyter笔记本中渲染表格时可以禁用 MathJax(GH 19856、GH 19824)DataFrame.replace()现在支持method参数,当to_replace是标量、列表或元组且value为None时,该参数可用于指定替换方法。(GH 19632)Timestamp.month_name()、DatetimeIndex.month_name()和Series.dt.month_name()现已可用(GH 12805)Timestamp.day_name()和DatetimeIndex.day_name()现已可用,用于返回指定区域设置的日期名称(GH 12806)DataFrame.to_sql()现在执行多值插入,如果底层连接支持,而不是逐行插入。SQLAlchemy方言支持多值插入的包括:mysql、postgresql、sqlite以及任何具有supports_multivalues_insert的方言。(GH 14315、GH 8953)read_html()现在接受displayed_only关键字参数,用于控制是否解析隐藏元素(默认为True)。(GH 20027)read_html()现在读取<table>中的所有<tbody>元素,而不仅仅是第一个。(GH 20690)Rolling.quantile()和Expanding.quantile()现在接受interpolation关键字,默认为linear(GH 20497)DataFrame.to_pickle()、Series.to_pickle()、DataFrame.to_csv()、Series.to_csv()、DataFrame.to_json()、Series.to_json()均支持通过compression=zip进行 zip 压缩。(GH 17778)WeekOfMonth构造函数现在支持n=0(GH 20517)。DataFrame和Series现在支持 Python>=3.5 的矩阵乘法 (@) 运算符。(GH 10259)更新了
DataFrame.to_gbq()和pandas.read_gbq()的签名和文档,以反映 pandas-gbq 库 0.4.0 版本的变更。添加了到 pandas-gbq 库的 intersphinx 映射。(GH 20564)添加了新写入器
StataWriter117,用于导出 117 版本的 Stata dta 文件。该格式支持导出长度最长达 2,000,000 个字符的字符串。(GH 16450)to_hdf()和read_hdf()现在接受errors关键字参数来控制编码错误处理(GH 20835)cut()增加了duplicates='raise'|'drop'选项,用于控制是否在重复边界上引发错误(GH 20947)date_range()、timedelta_range()和interval_range()现在在指定了start、stop和periods但未指定freq时,返回一个线性间隔的索引。(GH 20808、GH 20983、GH 20976)
向后不兼容的 API 变更#
依赖项的最低版本要求已提高#
我们已经更新了依赖项的最低支持版本(GH 15184)。如果已安装,我们现在要求:
包 |
最低版本 |
要求 |
问题 |
|---|---|---|---|
python-dateutil |
2.5.0 |
X |
|
openpyxl |
2.4.0 |
||
beautifulsoup4 |
4.2.1 |
||
setuptools |
24.2.0 |
Python 3.6+ 中从字典实例化时保留字典插入顺序#
在 Python 3.6 之前,Python 中的字典没有正式定义的顺序。对于 Python 3.6 及更高版本,字典按插入顺序排序,请参阅 PEP 468。当您从字典创建 Series 或 DataFrame 并且使用 Python 3.6 或更高版本时,pandas 将使用字典的插入顺序。(GH 19884)
旧行为(以及 Python < 3.6 时的当前行为)
In [16]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
Out[16]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
dtype: int64
请注意,上面的 Series 按索引值的字母顺序排列。
新行为(适用于 Python >= 3.6)
In [72]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
....:
Out[72]:
Income 2000
Expenses -1500
Taxes -200
Net result 300
Length: 4, dtype: int64
请注意,Series 现在按插入顺序排序。此新行为适用于所有相关的 pandas 类型(Series、DataFrame、SparseSeries 和 SparseDataFrame)。
如果您希望在 Python >= 3.6 时保留旧行为,可以使用 .sort_index()
In [73]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300}).sort_index()
....:
Out[73]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
Length: 4, dtype: int64
弃用 Panel#
Panel 在 0.20.x 版本中已被弃用,并显示为 DeprecationWarning。现在使用 Panel 将显示 FutureWarning。表示 3D 数据的推荐方式是使用 DataFrame 上的 MultiIndex 通过 to_frame() 方法,或者使用 xarray 包。pandas 提供了一个 to_xarray() 方法来自动化此转换(GH 13563、GH 18324)。
In [75]: import pandas._testing as tm
In [76]: p = tm.makePanel()
In [77]: p
Out[77]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
转换为 MultiIndex DataFrame
In [78]: p.to_frame()
Out[78]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.469112 0.721555 0.404705
B -1.135632 0.271860 -1.039268
C 0.119209 0.276232 -1.344312
D -2.104569 0.113648 -0.109050
2000-01-04 A -0.282863 -0.706771 0.577046
B 1.212112 -0.424972 -0.370647
C -1.044236 -1.087401 0.844885
D -0.494929 -1.478427 1.643563
2000-01-05 A -1.509059 -1.039575 -1.715002
B -0.173215 0.567020 -1.157892
C -0.861849 -0.673690 1.075770
D 1.071804 0.524988 -1.469388
[12 rows x 3 columns]
转换为 xarray DataArray
In [79]: p.to_xarray()
Out[79]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.469112, -1.135632, 0.119209, -2.104569],
[-0.282863, 1.212112, -1.044236, -0.494929],
[-1.509059, -0.173215, -0.861849, 1.071804]],
[[ 0.721555, 0.27186 , 0.276232, 0.113648],
[-0.706771, -0.424972, -1.087401, -1.478427],
[-1.039575, 0.56702 , -0.67369 , 0.524988]],
[[ 0.404705, -1.039268, -1.344312, -0.10905 ],
[ 0.577046, -0.370647, 0.844885, 1.643563],
[-1.715002, -1.157892, 1.07577 , -1.469388]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
移除 pandas.core.common 中的内容#
以下错误和警告消息已从 pandas.core.common 中移除(GH 13634、GH 19769)
PerformanceWarningUnsupportedFunctionCallUnsortedIndexErrorAbstractMethodError
这些可以从 pandas.errors 导入(自 0.19.0 起)。
使 DataFrame.apply 输出一致的变更#
DataFrame.apply() 在应用任意用户定义函数返回类列表对象时,当 axis=1 时存在不一致。若干错误和不一致性已得到解决。如果应用函数返回 Series,则 pandas 将返回 DataFrame;否则将返回 Series,这包括返回类列表对象(例如 tuple 或 list)的情况。(GH 16353、GH 17437、GH 17970、GH 17348、GH 17892、GH 18573、GH 17602、GH 18775、GH 18901、GH 18919)。
In [74]: df = pd.DataFrame(np.tile(np.arange(3), 6).reshape(6, -1) + 1,
....: columns=['A', 'B', 'C'])
....:
In [75]: df
Out[75]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
旧行为:如果返回的形状恰好与原始列的长度匹配,则会返回一个 DataFrame。如果返回的形状不匹配,则会返回一个包含列表的 Series。
In [3]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[3]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
In [4]: df.apply(lambda x: [1, 2], axis=1)
Out[4]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
dtype: object
新行为:当应用函数返回一个类列表对象时,现在将始终返回一个 Series。
In [76]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[76]:
0 [1, 2, 3]
1 [1, 2, 3]
2 [1, 2, 3]
3 [1, 2, 3]
4 [1, 2, 3]
5 [1, 2, 3]
Length: 6, dtype: object
In [77]: df.apply(lambda x: [1, 2], axis=1)
Out[77]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
Length: 6, dtype: object
要获得扩展列,您可以使用 result_type='expand'
In [78]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='expand')
Out[78]:
0 1 2
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
要将结果广播到原始列(对于正确长度的类列表对象的旧行为),您可以使用 result_type='broadcast'。形状必须与原始列匹配。
In [79]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='broadcast')
Out[79]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
返回 Series 允许控制确切的返回结构和列名
In [80]: df.apply(lambda x: pd.Series([1, 2, 3], index=['D', 'E', 'F']), axis=1)
Out[80]:
D E F
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
连接操作将不再排序#
在未来版本的 pandas 中,当非连接轴未对齐时,pandas.concat() 将不再对其进行排序。当前行为与以前相同(排序),但现在当未指定 sort 且非连接轴未对齐时,会发出警告。(GH 4588)
In [81]: df1 = pd.DataFrame({"a": [1, 2], "b": [1, 2]}, columns=['b', 'a'])
In [82]: df2 = pd.DataFrame({"a": [4, 5]})
In [83]: pd.concat([df1, df2])
Out[83]:
b a
0 1.0 1
1 2.0 2
0 NaN 4
1 NaN 5
[4 rows x 2 columns]
要保留旧行为(排序)并消除警告,请传入 sort=True
In [84]: pd.concat([df1, df2], sort=True)
Out[84]:
a b
0 1 1.0
1 2 2.0
0 4 NaN
1 5 NaN
[4 rows x 2 columns]
要接受未来行为(不排序),请传入 sort=False
请注意,此更改也适用于 DataFrame.append(),它也增加了用于控制此行为的 sort 关键字。
构建变更#
索引除以零的填充现在正确#
对 Index 及其子类进行除法运算时,正数除以零将填充 np.inf,负数除以零将填充 -np.inf,0 / 0 将填充 np.nan。这与现有的 Series 行为一致。(GH 19322,GH 19347)
旧行为
In [6]: index = pd.Int64Index([-1, 0, 1])
In [7]: index / 0
Out[7]: Int64Index([0, 0, 0], dtype='int64')
# Previous behavior yielded different results depending on the type of zero in the divisor
In [8]: index / 0.0
Out[8]: Float64Index([-inf, nan, inf], dtype='float64')
In [9]: index = pd.UInt64Index([0, 1])
In [10]: index / np.array([0, 0], dtype=np.uint64)
Out[10]: UInt64Index([0, 0], dtype='uint64')
In [11]: pd.RangeIndex(1, 5) / 0
ZeroDivisionError: integer division or modulo by zero
当前行为
In [12]: index = pd.Int64Index([-1, 0, 1])
# division by zero gives -infinity where negative,
# +infinity where positive, and NaN for 0 / 0
In [13]: index / 0
# The result of division by zero should not depend on
# whether the zero is int or float
In [14]: index / 0.0
In [15]: index = pd.UInt64Index([0, 1])
In [16]: index / np.array([0, 0], dtype=np.uint64)
In [17]: pd.RangeIndex(1, 5) / 0
从字符串中提取匹配模式#
默认情况下,使用 str.extract() 从字符串中提取匹配模式时,如果只提取一个组,则返回 Series(如果提取多个组,则返回 DataFrame)。从 pandas 0.23.0 开始,除非 expand 设置为 False,否则 str.extract() 始终返回 DataFrame。最后,None 曾是 expand 参数的接受值(等同于 False),但现在会引发 ValueError。(GH 11386)
旧行为
In [1]: s = pd.Series(['number 10', '12 eggs'])
In [2]: extracted = s.str.extract(r'.*(\d\d).*')
In [3]: extracted
Out [3]:
0 10
1 12
dtype: object
In [4]: type(extracted)
Out [4]:
pandas.core.series.Series
新行为
In [85]: s = pd.Series(['number 10', '12 eggs'])
In [86]: extracted = s.str.extract(r'.*(\d\d).*')
In [87]: extracted
Out[87]:
0
0 10
1 12
[2 rows x 1 columns]
In [88]: type(extracted)
Out[88]: pandas.core.frame.DataFrame
要恢复之前的行为,只需将 expand 设置为 False
In [89]: s = pd.Series(['number 10', '12 eggs'])
In [90]: extracted = s.str.extract(r'.*(\d\d).*', expand=False)
In [91]: extracted
Out[91]:
0 10
1 12
Length: 2, dtype: object
In [92]: type(extracted)
Out[92]: pandas.core.series.Series
CategoricalDtype 的 ordered 参数的默认值#
CategoricalDtype 的 ordered 参数的默认值已从 False 更改为 None,以允许更新 categories 而不影响 ordered。下游对象(如 Categorical)的行为应保持一致。(GH 18790)
在以前的版本中,ordered 参数的默认值为 False。这可能导致当用户尝试更新 categories 且未明确指定 ordered 时,ordered 参数意外地从 True 更改为 False,因为它会默默地默认为 False。ordered=None 的新行为是保留 ordered 的现有值。
新行为
In [2]: from pandas.api.types import CategoricalDtype
In [3]: cat = pd.Categorical(list('abcaba'), ordered=True, categories=list('cba'))
In [4]: cat
Out[4]:
[a, b, c, a, b, a]
Categories (3, object): [c < b < a]
In [5]: cdt = CategoricalDtype(categories=list('cbad'))
In [6]: cat.astype(cdt)
Out[6]:
[a, b, c, a, b, a]
Categories (4, object): [c < b < a < d]
注意在上面的示例中,转换后的 Categorical 保留了 ordered=True。如果 ordered 的默认值仍为 False,那么转换后的 Categorical 将变为无序的,尽管从未明确指定 ordered=False。要更改 ordered 的值,请将其明确传递给新的 dtype,例如 CategoricalDtype(categories=list('cbad'), ordered=False)。
请注意,上面讨论的 ordered 的意外转换在以前的版本中并未出现,因为存在单独的错误,阻止了 astype 进行任何类型的类别到类别转换(GH 10696,GH 18593)。这些错误已在此版本中修复,并促使更改 ordered 的默认值。
在终端中更好地美化打印 DataFrame#
以前,最大列数的默认值为 pd.options.display.max_columns=20。这意味着相对较宽的 DataFrame 无法在终端宽度内完全显示,并且 pandas 会引入换行符来显示这20列。这导致输出相对难以阅读
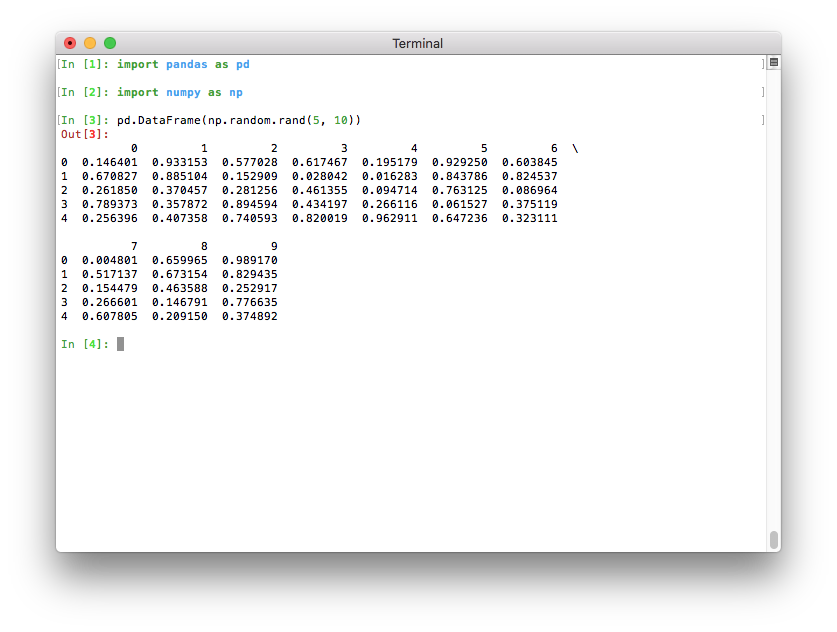
如果 Python 在终端中运行,最大列数现在会自动确定,以便打印的 DataFrame 适合当前终端宽度(pd.options.display.max_columns=0)(GH 17023)。如果 Python 作为 Jupyter 内核运行(例如 Jupyter QtConsole 或 Jupyter notebook,以及许多 IDE 中),则无法自动推断此值,因此会像以前的版本一样设置为 20。在终端中,这会产生更好的输出
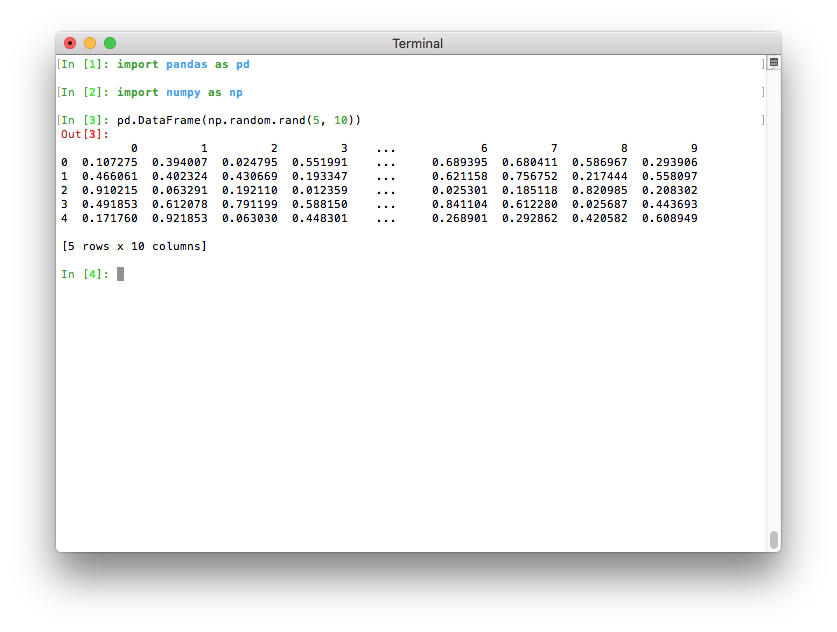
请注意,如果您不喜欢新的默认设置,您始终可以自行设置此选项。要恢复旧设置,您可以运行此行
pd.options.display.max_columns = 20
日期时间类 API 更改#
默认的
Timedelta构造函数现在接受ISO 8601 Duration字符串作为参数(GH 19040)从
dtype='datetime64[ns]'的Series中减去NaT将返回dtype='timedelta64[ns]'的Series,而不是dtype='datetime64[ns]'(GH 18808)从
TimedeltaIndex中添加或减去NaT将返回TimedeltaIndex,而不是DatetimeIndex(GH 19124)当索引对象频率为
None时,DatetimeIndex.shift()和TimedeltaIndex.shift()现在将引发NullFrequencyError(它是ValueError的子类,旧版本中会引发ValueError)(GH 19147)从
dtype='timedelta64[ns]'的Series中添加和减去NaN将引发TypeError,而不是将NaN视为NaT(GH 19274)NaT与datetime.timedelta进行除法运算现在将返回NaN而不是引发错误(GH 17876)dtype='datetime64[ns]'的Series与PeriodIndex之间的操作将正确引发TypeError(GH 18850)时区不匹配的时区感知
dtype='datetime64[ns]'的Series的减法将引发TypeError而不是ValueError(GH 18817)CacheableOffset和WeekDay不再在pandas.tseries.offsets模块中可用(GH 17830)pandas.tseries.frequencies.get_freq_group()和pandas.tseries.frequencies.DAYS已从公共 API 中移除(GH 18034)如果索引未排序,
Series.truncate()和DataFrame.truncate()将引发ValueError,而不是无用的KeyError(GH 17935)当索引不是
DatetimeIndex时,Series.first和DataFrame.first现在将引发TypeError而不是NotImplementedError。(GH 20725)。当索引不是
DatetimeIndex时,Series.last和DataFrame.last现在将引发TypeError而不是NotImplementedError。(GH 20725)。限制了
DateOffset关键字参数。以前,DateOffset子类允许任意关键字参数,这可能导致意外行为。现在,只接受有效参数。(GH 17176, GH 18226)。当尝试合并时区感知和时区非感知列时,
pandas.merge()会提供更具信息量的错误消息(GH 15800)对于
freq=None的DatetimeIndex和TimedeltaIndex,整数类型数组或Index的加法或减法将引发NullFrequencyError而不是TypeError(GH 19895)在实例化后设置
tz属性时,DatetimeIndex现在将引发AttributeError(GH 3746)带有
pytz时区的DatetimeIndex现在将返回一致的pytz时区(GH 18595)
其他 API 更改#
使用不兼容 dtype 的
Series.astype()和Index.astype()现在将引发TypeError而不是ValueError(GH 18231)使用
object类型且时区感知的 datetime 和指定dtype=object构建Series时,现在将返回object类型的Series,以前会推断为 datetime 类型(GH 18231)从空
dict构建的dtype=category的Series,其类别现在将是dtype=object而不是dtype=float64,这与传递空列表的情况一致(GH 18515)MultiIndex中所有为 NaN 的级别现在被指定为float类型而不是object类型,以提高与Index的一致性(GH 17929)。MultiIndex的级别名称(当不为 None 时)现在必须是唯一的:尝试使用重复名称创建MultiIndex将引发ValueError(GH 18872)使用不可哈希的
name/names构建和重命名Index/MultiIndex现在都将引发TypeError(GH 20527)Index.map()现在可以接受Series和字典输入对象(GH 12756, GH 18482, GH 18509)。DataFrame.unstack()现在将默认为object列填充np.nan。(GH 12815)如果
closed参数与输入数据推断的闭合方式冲突,IntervalIndex构造函数将引发错误(GH 18421)将缺失值插入到索引中将适用于所有类型的索引,并自动插入正确类型的缺失值(
NaN、NaT等),无论传入的类型是什么(GH 18295)当使用重复标签创建时,
MultiIndex现在会引发ValueError。(GH 17464)当将列表、元组或 DataFrame 作为
value传入时,Series.fillna()现在会引发TypeError而不是ValueError(GH 18293)当在
int和float列上合并时,pandas.DataFrame.merge()不再将float列转换为object类型(GH 16572)当尝试合并不兼容的数据类型时,
pandas.merge()现在会引发ValueError(GH 9780)UInt64Index的默认 NA 值已从 0 更改为NaN,这会影响使用 NA 进行掩码的方法,例如UInt64Index.where()(GH 18398)重构了
setup.py,使用find_packages而不是显式列出所有子包(GH 18535)重新排列了
read_excel()中的关键字参数顺序,使其与read_csv()对齐(GH 16672)wide_to_long()以前将类似数字的后缀保留为object类型。现在,如果可能,它们会被转换为数字类型(GH 17627)在
read_excel()中,comment参数现在作为命名参数公开(GH 18735)重新排列了
read_excel()中的关键字参数顺序,使其与read_csv()对齐(GH 16672)选项
html.border和mode.use_inf_as_null在之前的版本中已弃用,现在它们将显示FutureWarning而不是DeprecationWarning(GH 19003)IntervalIndex和IntervalDtype不再支持 categorical、object 和 string 子类型(GH 19016)无论子类型如何,
IntervalDtype现在与'interval'比较时都返回True,并且IntervalDtype.name现在无论子类型如何都返回'interval'(GH 18980)当删除具有重复项的轴中不存在的元素时,
drop(),drop(),drop(),drop()现在会引发KeyError而不是ValueError(GH 19186)Series.to_csv()现在接受一个compression参数,其工作方式与DataFrame.to_csv()中的compression参数相同(GH 18958)对具有不兼容索引类型的
IntervalIndex执行集合操作(union、difference 等)现在将引发TypeError而不是ValueError(GH 19329)DateOffset对象的渲染更简单,例如<DateOffset: days=1>而不是<DateOffset: kwds={'days': 1}>(GH 19403)Categorical.fillna现在会验证其value和method关键字参数。当同时指定或均未指定时,它会引发错误,这与Series.fillna()的行为一致(GH 19682)pd.to_datetime('today')现在返回一个 datetime 对象,与pd.Timestamp('today')一致;以前pd.to_datetime('today')返回一个.normalized()datetime(GH 19935)Series.str.replace()现在接受一个可选的regex关键字,当设置为False时,使用字面字符串替换而不是正则表达式替换(GH 16808)DatetimeIndex.strftime()和PeriodIndex.strftime()现在返回Index而不是 numpy 数组,以与类似的访问器保持一致(GH 20127)对于仅包含 int 和 float 列的 DataFrame,使用
orient='index'的DataFrame.to_dict()不再将 int 列转换为 float 类型(GH 18580)传递给
Series.rolling().aggregate()、DataFrame.rolling().aggregate()或其 expanding 对应函数的用户定义函数,现在将总是被传递一个Series,而不是np.array;.apply()只拥有raw关键字,详见此处。这与 pandas 中.aggregate()的签名一致(GH 20584)Rolling 和 Expanding 类型在迭代时会引发
NotImplementedError(GH 11704)。
弃用项#
Series.from_array和SparseSeries.from_array已弃用。请改用常规构造函数Series(..)和SparseSeries(..)(GH 18213)。DataFrame.as_matrix已弃用。请改用DataFrame.values(GH 18458)。Series.asobject、DatetimeIndex.asobject、PeriodIndex.asobject和TimeDeltaIndex.asobject已弃用。请改用.astype(object)(GH 18572)现在,按键元组进行分组会发出
FutureWarning并已弃用。将来,传递给'by'的元组将始终引用实际的元组作为单个键,而不是将元组视为多个键。要保留以前的行为,请使用列表而不是元组(GH 18314)Series.valid已弃用。请改用Series.dropna()(GH 18800)。read_excel()已弃用skip_footer参数。请改用skipfooter(GH 18836)ExcelFile.parse()已弃用sheetname,推荐使用sheet_name以与read_excel()保持一致(GH 20920)。is_copy属性已弃用,并将在未来版本中移除(GH 18801)。IntervalIndex.from_intervals已弃用,推荐使用IntervalIndex构造函数(GH 19263)DataFrame.from_items已弃用。请改用DataFrame.from_dict(),如果您希望保留键的顺序,则使用DataFrame.from_dict(OrderedDict())(GH 17320, GH 17312)使用包含某些缺失键的列表索引
MultiIndex或FloatIndex现在将显示FutureWarning,这与其他类型的索引一致(GH 17758)。.apply()的broadcast参数已弃用,推荐使用result_type='broadcast'(GH 18577).apply()的reduce参数已弃用,推荐使用result_type='reduce'(GH 18577)factorize()的order参数已弃用,并将在未来版本中移除(GH 19727)Timestamp.weekday_name、DatetimeIndex.weekday_name和Series.dt.weekday_name已弃用,推荐使用Timestamp.day_name()、DatetimeIndex.day_name()和Series.dt.day_name()(GH 12806)pandas.tseries.plotting.tsplot已弃用。请改用Series.plot()(GH 18627)Index.summary()已弃用,并将在未来版本中移除(GH 18217)NDFrame.get_ftype_counts()已弃用,并将在未来版本中移除(GH 18243)DataFrame.to_records()中的convert_datetime64参数已弃用,并将在未来版本中移除。导致此参数的 NumPy 错误已解决。此参数的默认值也已从True更改为None(GH 18160)。Series.rolling().apply()、DataFrame.rolling().apply()、Series.expanding().apply()和DataFrame.expanding().apply()已弃用默认传递np.array。现在需要传递新的raw参数来明确指定传递的内容(GH 20584)Series和Index类的data、base、strides、flags和itemsize属性已弃用,并将在未来版本中移除(GH 20419)。DatetimeIndex.offset已弃用。请改用DatetimeIndex.freq(GH 20716)整数 ndarray 与
Timedelta之间的整除已弃用。请改用Timedelta.value进行除法运算(GH 19761)设置
PeriodIndex.freq(以前不保证能正确工作)已弃用。请改用PeriodIndex.asfreq()(GH 20678)Index.get_duplicates()已弃用,并将在未来版本中移除(GH 20239)Categorical.take中负数索引的先前默认行为已弃用。在未来版本中,它将从表示缺失值更改为表示从右侧开始的位置索引。未来的行为与Series.take()一致(GH 20664)。在
DataFrame.dropna()中将多个轴传递给axis参数已弃用,并将在未来版本中移除(GH 20987)
移除以前版本的弃用/更改#
针对已废弃的用法
Categorical(codes, categories)的警告(例如当Categorical()的前两个参数具有不同 dtype 时发出,并推荐使用Categorical.from_codes)现已移除(GH 8074)MultiIndex的levels和labels属性不再能直接设置(GH 4039)。pd.tseries.util.pivot_annual已移除(自 v0.19 起弃用)。请改用pivot_table(GH 18370)pd.tseries.util.isleapyear已移除(自 v0.19 起弃用)。请改用 Datetime-likes 中的.is_leap_year属性(GH 18370)pd.ordered_merge已移除(自 v0.19 起弃用)。请改用pd.merge_ordered(GH 18459)SparseList类已移除(GH 14007)pandas.io.wb和pandas.io.data存根模块已移除(GH 13735)Categorical.from_array已移除(GH 13854)freq和how参数已从 DataFrame 和 Series 的rolling/expanding/ewm方法中移除(自 v0.18 起弃用)。请改在调用方法之前进行重采样。(GH 18601 & GH 18668)DatetimeIndex.to_datetime、Timestamp.to_datetime、PeriodIndex.to_datetime和Index.to_datetime已移除(GH 8254、GH 14096、GH 14113)read_csv()已移除skip_footer参数(GH 13386)read_csv()已移除as_recarray参数 (GH 13373)read_csv()已移除buffer_lines参数 (GH 13360)read_csv()已移除compact_ints和use_unsigned参数 (GH 13323)The
Timestamp类已移除offset属性,转而使用freq(GH 13593)The
Series、Categorical和Index类已移除reshape方法 (GH 13012)pandas.tseries.frequencies.get_standard_freq已被移除,转而使用pandas.tseries.frequencies.to_offset(freq).rule_code(GH 13874)The
freqstr关键字已从pandas.tseries.frequencies.to_offset中移除,转而使用freq(GH 13874)The
Panel4D和PanelND类已被移除 (GH 13776)The
Panel类已移除to_long和toLong方法 (GH 19077)The options
display.line_with和display.height已被移除,转而分别使用display.width和display.max_rows(GH 4391, GH 19107)The
Categorical类的labels属性已移除,转而使用Categorical.codes(GH 7768)The
flavor参数已从to_sql()方法中移除 (GH 13611)The modules
pandas.tools.hashing和pandas.util.hashing已被移除 (GH 16223)The top-level functions
pd.rolling_*、pd.expanding_*和pd.ewm*已被移除(自 v0.18 起已弃用)。请转而使用 DataFrame/Series 方法rolling、expanding和ewm(GH 18723)Imports from
pandas.core.commonfor functions such asis_datetime64_dtype现已移除。这些函数位于pandas.api.types中。(GH 13634, GH 19769)The
infer_dst关键字在Series.tz_localize()、DatetimeIndex.tz_localize()和DatetimeIndex中已移除。infer_dst=True等同于ambiguous='infer',infer_dst=False等同于ambiguous='raise'(GH 7963)。When
.resample()从急切操作(eager operation)更改为惰性操作(lazy operation),像 v0.18.0 中的.groupby()一样时,我们为了兼容性(带有FutureWarning)而进行了一些调整,以确保操作能够继续进行。现在,此兼容性已完全移除,因此Resampler将不再转发兼容操作 (GH 20554)移除
.replace()中长期弃用的axis=None参数 (GH 20271)
性能改进#
Indexers on
Series或DataFrame不再创建引用循环 (GH 17956)为
to_datetime()添加了一个关键字参数cache,它改进了转换重复 datetime 参数的性能 (GH 11665)DateOffset算术运算性能得到改进 (GH 18218)将
Timedelta对象的Series转换为天、秒等的操作通过底层方法的向量化而加速 (GH 18092)改进了
.map()在Series/dict输入下的性能 (GH 15081)已移除被重写的
Timedelta天、秒和微秒属性,转而利用其内置的 Python 版本 (GH 18242)Series的构造将减少输入数据在某些情况下的复制数量 (GH 17449)改进了
Series.dt.date()和DatetimeIndex.date()的性能 (GH 18058)改进了
Series.dt.time()和DatetimeIndex.time()的性能 (GH 18461)改进了
IntervalIndex.symmetric_difference()的性能 (GH 18475)改进了
DatetimeIndex和Series在商业月和商业季度频率下的算术运算性能 (GH 18489)Series()/DataFrame()的 Tab 自动补全限制为 100 个值,以获得更好的性能。(GH 18587)改进了当未安装 bottleneck 时,
DataFrame.median()在axis=1下的性能 (GH 16468)改进了
MultiIndex.get_loc()对大型索引的性能,但代价是小型索引的性能有所下降 (GH 18519)改进了
MultiIndex.remove_unused_levels()在没有未使用的级别时的性能,但代价是在存在未使用的级别时性能有所下降 (GH 19289)改进了
Index.get_loc()对非唯一索引的性能 (GH 19478)改进了成对的
.rolling()和.expanding()搭配.cov()和.corr()操作的性能 (GH 17917)改进了
GroupBy.rank()的性能 (GH 15779)改进了
.rolling()在.min()和.max()上的可变性能 (GH 19521)改进了
GroupBy.ffill()和GroupBy.bfill()的性能 (GH 11296)改进了
GroupBy.any()和GroupBy.all()的性能 (GH 15435)改进了
GroupBy.pct_change()的性能 (GH 19165)改进了
Series.isin()在分类 dtype 情况下的性能 (GH 20003)改进了
getattr(Series, attr)在 Series 具有某些索引类型时的性能。这表现为DatetimeIndex的大型 Series 打印缓慢的问题 (GH 19764)修复了
GroupBy.nth()和GroupBy.last()在某些对象列上的性能回归问题 (GH 19283)改进了
Categorical.from_codes()的性能 (GH 18501)
文档变更#
感谢所有参与 3 月 10 日 pandas 文档冲刺活动的贡献者。我们有来自全球 30 多个地点的约 500 名参与者。您应该会注意到许多 API docstrings 已得到极大改进。
同时进行的贡献太多,无法为每项改进都包含发布说明,但此 GitHub search 能让您了解有多少文档字符串得到了改进。
特别感谢 Marc Garcia 组织了这次冲刺活动。欲了解更多信息,请阅读 NumFOCUS blogpost,该文章总结了本次冲刺活动。
缺陷修复#
Categorical#
警告
pandas 0.21 中引入了一类与 CategoricalDtype 相关的缺陷,影响了 merge、concat 和索引等操作的正确性,尤其是在比较多个具有相同类别但顺序不同的无序 Categorical 数组时。我们强烈建议在执行这些操作之前升级或手动对齐您的类别。
Categorical.equals的缺陷:当比较两个具有相同类别但顺序不同的无序Categorical数组时,返回错误结果 (GH 16603)pandas.api.types.union_categoricals()的缺陷:对于类别顺序不同的无序分类数据,返回错误结果。这影响了pandas.concat()处理 Categorical 数据时的行为 (GH 19096)。pandas.merge()的缺陷:当基于具有相同类别但顺序不同的无序Categorical进行连接时,返回错误结果 (GH 19551)CategoricalIndex.get_indexer()的缺陷:当target是一个与self具有相同类别但顺序不同的无序Categorical时,返回错误结果 (GH 19551)Index.astype()的缺陷:当使用分类 dtype 时,生成的索引未对所有类型的索引都转换为CategoricalIndex(GH 18630)Series.astype()和Categorical.astype()的缺陷:现有分类数据未更新 (GH 10696, GH 18593)Series.str.split()的缺陷:当expand=True时,在空字符串上错误地引发 IndexError (GH 20002)。Index构造函数的缺陷:当使用dtype=CategoricalDtype(...)时,categories和ordered未被保留 (GH 19032)Series构造函数的缺陷:当使用标量和dtype=CategoricalDtype(...)时,categories和ordered未被保留 (GH 19565)Categorical.__iter__的缺陷:未转换为 Python 类型 (GH 19909)pandas.factorize()的缺陷:返回uniques的唯一编码。现在返回一个与输入具有相同 dtype 的Categorical(GH 19721)pandas.factorize()的缺陷:在uniques返回值中包含了缺失值项 (GH 19721)Series.take()的缺陷:当处理分类数据时,错误地将-1在indices中解释为缺失值标记,而非 Series 的最后一个元素 (GH 20664)
日期时间类 (Datetimelike)#
Series.__sub__()的缺陷:从Series中减去非纳秒np.datetime64对象时,结果不正确 (GH 7996)DatetimeIndex、TimedeltaIndex的缺陷:添加和减去零维整数数组时,结果不正确 (GH 19012)DatetimeIndex和TimedeltaIndex的缺陷:添加或减去类数组的DateOffset对象时,要么引发异常(np.array,pd.Index),要么广播不正确(pd.Series)(GH 18849)Series.__add__()的缺陷:将 dtype 为timedelta64[ns]的 Series 添加到时区感知DatetimeIndex时,错误地丢失了时区信息 (GH 13905)将
Period对象添加到datetime或Timestamp对象时,现在将正确地引发TypeError(GH 17983)Timestamp的缺陷:与Timestamp对象数组进行比较时,会导致RecursionError(GH 15183)DatetimeIndex的缺陷:在一天结束时 (例如 23:59:59.999999999) repr 未显示高精度时间值 (GH 19030).astype()的缺陷:转换为非纳秒 timedelta 单位时,会保留不正确的 dtype (GH 19176, GH 19223, GH 12425)Series.truncate()的缺陷:在单调PeriodIndex下引发TypeError(GH 17717)pct_change()的缺陷:使用periods和freq时返回不同长度的输出 (GH 7292)DatetimeIndex比较的缺陷:与None或datetime.date对象进行==和!=比较时,错误地引发TypeError,而非分别返回全False和全True(GH 19301)Timestamp和to_datetime()的缺陷:表示略微超出范围的时间戳字符串会被错误地向下舍入,而非引发OutOfBoundsDatetime(GH 19382)Timestamp.floor()和DatetimeIndex.floor()的缺陷:遥远未来和过去的时间戳未正确舍入 (GH 19206)to_datetime()的缺陷:当传递超出范围的 datetime 且设置errors='coerce'和utc=True时,会引发OutOfBoundsDatetime而非解析为NaT(GH 19612)DatetimeIndex和TimedeltaIndex的缺陷:在加减运算中,返回对象的名称并非始终一致地设置 (GH 19744)DatetimeIndex和TimedeltaIndex的缺陷:与 numpy 数组进行加减运算时引发TypeError(GH 19847)DatetimeIndex和TimedeltaIndex的缺陷:设置freq属性未得到完全支持 (GH 20678)
Timedelta#
Timedelta.__mul__()的缺陷:乘以NaT时,返回NaT而非引发TypeError(GH 19819)Series的缺陷:当 dtype 为timedelta64[ns]时,与TimedeltaIndex进行加减运算的结果被强制转换为dtype='int64'(GH 17250)Series的缺陷:当 dtype 为timedelta64[ns]时,与TimedeltaIndex进行加减运算可能会返回一个名称不正确的Series(GH 19043)Timedelta.__floordiv__()和Timedelta.__rfloordiv__()的缺陷:错误地允许除以许多不兼容的 numpy 对象 (GH 18846)缺陷:用
TimedeltaIndex除以标量 timedelta 类对象时,执行了倒数运算 (GH 19125)TimedeltaIndex的缺陷:除以Series时会返回TimedeltaIndex而非Series(GH 19042)Timedelta.__add__()、Timedelta.__sub__()的缺陷:添加或减去np.timedelta64对象时,会返回另一个np.timedelta64而非Timedelta(GH 19738)Timedelta.__floordiv__()、Timedelta.__rfloordiv__()的缺陷:与Tick对象进行操作时会引发TypeError而非返回数值 (GH 19738)Period.asfreq()的缺陷:接近datetime(1, 1, 1)的周期可能会被错误转换 (GH 19643, GH 19834)Timedelta.total_seconds()的缺陷:导致精度错误,例如Timedelta('30S').total_seconds()==30.000000000000004(GH 19458)Timedelta.__rmod__()的缺陷:与numpy.timedelta64进行操作时,返回timedelta64对象而非Timedelta(GH 19820)TimedeltaIndex乘以TimedeltaIndex现在将引发TypeError,而非在长度不匹配时引发ValueError(GH 19333)索引
TimedeltaIndex与np.timedelta64对象时的缺陷:会引发TypeError(GH 20393)
时区 (Timezones)#
从包含时区天真(tz-naive)和时区感知(tz-aware)值的数组创建
Series时的缺陷:将导致Series的 dtype 为时区感知,而非对象 (GH 16406)时区感知
DatetimeIndex与NaT比较时的缺陷:错误地引发TypeError(GH 19276)DatetimeIndex.astype()的缺陷:在时区感知 dtype 之间转换时,以及从时区感知转换为天真时区时出现问题 (GH 18951)DatetimeIndex比较的缺陷:尝试比较时区感知和时区天真日期时间类对象时,未能引发TypeError(GH 18162)Series构造函数中使用datetime64[ns, tz]dtype 对天真时区日期时间字符串进行本地化时的缺陷 (GH 174151)Timestamp.replace()现在将优雅地处理夏令时转换 (GH 18319)时区感知
DatetimeIndex的缺陷:与TimedeltaIndex或 dtype 为timedelta64[ns]的数组进行加减运算不正确 (GH 17558)DatetimeIndex.insert()的缺陷:将NaT插入时区感知索引时错误地引发了异常 (GH 16357)DataFrame构造函数的缺陷:当使用时区感知 Datetimeindex 和给定列名时,会导致一个空的DataFrame(GH 19157)Timestamp.tz_localize()的缺陷:本地化接近最小或最大有效值的时间戳时,可能会溢出并返回一个具有不正确纳秒值的时间戳 (GH 12677)迭代通过固定时区偏移量进行本地化,并将其纳秒精度舍入为微秒的
DatetimeIndex时的缺陷 (GH 19603)DataFrame.diff()的缺陷:使用时区感知值时引发IndexError(GH 18578)Dataframe.count()的缺陷:如果对具有时区感知值的单列调用Dataframe.dropna(),则会引发ValueError(GH 13407)。
偏移量 (Offsets)#
WeekOfMonth和Week的缺陷:加减运算未正确滚动 (GH 18510, GH 18672, GH 18864)WeekOfMonth和LastWeekOfMonth的缺陷:构造函数的默认关键字参数引发ValueError(GH 19142)FY5253Quarter、LastWeekOfMonth的缺陷:回滚和前滚行为与加减行为不一致 (GH 18854)FY5253的缺陷:年末日期但未规范化到午夜的datetime加减运算递增不正确 (GH 18854)FY5253的缺陷:日期偏移量在算术运算中可能错误地引发AssertionError(GH 14774)
数值 (Numeric)#
Series构造函数的缺陷:当使用整数或浮点数列表并指定dtype=str、dtype='str'或dtype='U'时,未能将数据元素转换为字符串 (GH 16605)Index乘法和除法方法的缺陷:与Series进行操作时,会返回Index对象而非Series对象 (GH 19042)DataFrame构造函数的缺陷:包含非常大正数或非常大负数的数据导致OverflowError(GH 18584)Index构造函数的缺陷:当dtype='uint64'时,类整数浮点数未被强制转换为UInt64Index(GH 18400)DataFrame灵活算术运算(例如df.add(other, fill_value=foo))的缺陷:当fill_value不为None时,在 frame 或other长度为零的极端情况下未能引发NotImplementedError(GH 19522)数值型 dtype 的
Index对象与 timedelta 类标量进行乘法和除法运算时,返回TimedeltaIndex而非引发TypeError(GH 19333)缺陷:当
fill_method不为None时,Series.pct_change()和DataFrame.pct_change()返回NaN而非 0 (GH 19873)
字符串 (Strings)#
Series.str.get()的缺陷:当值中包含字典且索引不在键中时,引发KeyError(GH 20671)
索引 (Indexing)#
Index.drop()的缺陷:当传入元组和非元组的混合列表时 (GH 18304)DataFrame.drop()、Panel.drop()、Series.drop()、Index.drop()的缺陷:当从包含重复项的轴中删除不存在的元素时,未引发KeyError(GH 19186)索引日期时间类
Index时的缺陷:引发ValueError而非IndexError(GH 18386)。Index.to_series()现在接受index和name关键字参数 (GH 18699)DatetimeIndex.to_series()现在接受index和name关键字参数 (GH 18699)索引非唯一
Index的Series中的非标量值时,会返回扁平化后的值 (GH 17610)索引仅包含缺失键的迭代器时的缺陷:未引发错误 (GH 20748)
修复了当索引具有整数 dtype 且不包含所需键时,
.ix在列表键和标量键之间不一致的问题 (GH 20753)str.extractall的缺陷:当没有匹配项时,返回空的Index而非适当的MultiIndex(GH 19034)IntervalIndex的缺陷:空数据和纯 NA 数据的构造方法不一致,取决于具体的构造方法 (GH 18421)IntervalIndex.symmetric_difference()的缺陷:与非IntervalIndex的对称差未引发异常 (GH 18475)IntervalIndex的缺陷:返回空IntervalIndex的集合操作具有错误的 dtype (GH 19101)DataFrame.drop_duplicates()的缺陷:当传入 DataFrame 中不存在的列时,未引发KeyError(GH 19726)Index子类构造函数的缺陷:忽略了意外的关键字参数 (GH 19348)Index.difference()的缺陷:当Index与自身取差集时 (GH 20040)DataFrame.first_valid_index()和DataFrame.last_valid_index()的缺陷:当值中间存在整行 NaN 时 (GH 20499)。IntervalIndex的缺陷:某些索引操作不支持重叠或非单调的uint64数据 (GH 20636)Series.is_unique的缺陷:如果 Series 包含定义了__ne__的对象,则会在 stderr 中显示额外输出 (GH 20661).loc赋值的缺陷:使用单元素类列表错误地赋值为列表 (GH 19474)在具有单调递减
DatetimeIndex的Series/DataFrame上进行部分字符串索引时的缺陷 (GH 19362)对具有重复
Index的DataFrame执行原地操作时的缺陷 (GH 17105)IntervalIndex.get_loc()和IntervalIndex.get_indexer()的缺陷:当与包含单个区间的IntervalIndex一起使用时 (GH 17284, GH 20921).loc赋值的缺陷:当使用uint64索引器时 (GH 20722)
MultiIndex#
MultiIndex.__contains__()的缺陷:非元组键即使已被删除也会返回True(GH 19027)MultiIndex.set_labels()的缺陷:如果level参数不是 0 或 [0, 1, …] 这样的列表,则会导致新标签的类型转换(以及潜在的剪裁)(GH 19057)MultiIndex.get_level_values()的缺陷:在整数级别上,当存在缺失值时会返回无效索引 (GH 17924)MultiIndex.unique()的缺陷:当在空的MultiIndex上调用时 (GH 20568)MultiIndex.unique()的缺陷:未保留级别名称 (GH 20570)MultiIndex.remove_unused_levels()的缺陷:会填充 NaN 值 (GH 18417)MultiIndex.from_tuples()的缺陷:在 Python 3 中未能接受压缩的元组 (GH 18434)MultiIndex.get_loc()的缺陷:未能自动将浮点数和整数之间的值进行类型转换 (GH 18818, GH 15994)MultiIndex.get_loc()的缺陷:将布尔值转换为整数标签 (GH 19086)MultiIndex.get_loc()的缺陷:未能定位包含NaN的键 (GH 18485)MultiIndex.get_loc()在大型MultiIndex中的缺陷:当级别具有不同 dtype 时会失败 (GH 18520)索引的缺陷:仅包含 numpy 数组的嵌套索引器处理不正确 (GH 19686)
IO#
read_html()现在在解析失败后、尝试使用新解析器解析之前,会倒回可查找的 IO 对象。如果解析器出错且对象不可查找,则会引发一个信息性错误,建议使用不同的解析器 (GH 17975)DataFrame.to_html()现在提供一个选项,可以在开头的<table>标签中添加 id (GH 8496)read_msgpack()的缺陷:在 Python 2 中传入不存在的文件时 (GH 15296)read_csv()的缺陷:具有重复列的MultiIndex未被正确处理 (GH 18062)read_csv()的缺陷:当keep_default_na=False且使用字典na_values时,缺失值未被正确处理 (GH 19227)read_csv()的缺陷:在 32 位大端架构上导致堆损坏 (GH 20785)read_sas()的缺陷:变量数为 0 的文件错误地引发了AttributeError。现在会引发EmptyDataError(GH 18184)在
DataFrame.to_latex()中存在一个错误,旨在用作隐形占位符的花括号对被转义 (GH 18667)在
DataFrame.to_latex()中存在一个错误,当 `MultiIndex` 中存在NaN时会导致IndexError或不正确输出 (GH 14249)在
DataFrame.to_latex()中存在一个错误,当索引级别名称为非字符串时会导致AttributeError(GH 19981)在
DataFrame.to_latex()中存在一个错误,索引名称与index_names=False选项的组合会导致不正确输出 (GH 18326)在
DataFrame.to_latex()中存在一个错误,当 `MultiIndex` 的名称为空字符串时会导致不正确输出 (GH 18669)在
DataFrame.to_latex()中存在一个错误,缺失的空格字符导致错误的转义,并在某些情况下生成无效的LaTeX (GH 20859)在
read_json()中存在一个错误,大数值会导致OverflowError(GH 18842)在
DataFrame.to_parquet()中存在一个错误,如果写入目标是 S3 则会引发异常 (GH 19134)Interval现在在DataFrame.to_excel()中支持所有 Excel 文件类型 (GH 19242)Timedelta现在在DataFrame.to_excel()中支持所有 Excel 文件类型 (GH 19242, GH 9155, GH 19900)在
pandas.io.stata.StataReader.value_labels()中存在一个错误,在处理非常旧的文件时会引发AttributeError。现在返回一个空字典 (GH 19417)在
read_pickle()中存在一个错误,当解封使用 pandas 0.20 版本之前创建的包含TimedeltaIndex或Float64Index的对象时 (GH 19939)在
pandas.io.json.json_normalize()中存在一个错误,当任何子记录的值为 NoneType 时,子记录无法正确规范化 (GH 20030)在
read_csv()的usecols参数中存在一个错误,传递字符串时未正确引发错误。 (GH 20529)在
HDFStore.keys()中存在一个错误,读取包含软链接的文件时导致异常 (GH 20523)在
HDFStore.select_column()中存在一个错误,当键不是有效存储时,引发了AttributeError而不是KeyError(GH 17912)
绘图#
当尝试绘图但未安装matplotlib时,显示更友好的错误消息 (GH 19810)。
DataFrame.plot()现在在x或y参数格式不正确时会引发ValueError(GH 18671)在
DataFrame.plot()中存在一个错误,当x和y参数以位置形式给出时,导致折线图、条形图和面积图的引用列不正确 (GH 20056)使用
datetime.time()和小数秒格式化刻度标签时出错 (GH 18478)。Series.plot.kde()在文档字符串中公开了参数ind和bw_method(GH 18461)。参数ind现在也可以是整数(样本点数量)。DataFrame.plot()现在支持y参数接收多列 (GH 19699)
GroupBy/重采样/滚动#
按单列分组并使用
list或tuple等类进行聚合时出错 (GH 18079)修复了
DataFrame.groupby()中的回归问题,该问题在调用时使用不在索引中的元组键不会发出错误 (GH 18798)在
DataFrame.resample()中存在一个错误,它默默地忽略了label、closed和convention的(不受支持或拼写错误的)选项 (GH 19303)在
DataFrame.groupby()中存在一个错误,元组被解释为键列表而不是单个键 (GH 17979, GH 18249)在
DataFrame.groupby()中存在一个错误,通过first/last/min/max聚合导致时间戳精度丢失 (GH 19526)在
DataFrame.transform()中存在一个错误,某些聚合函数被错误地转换为匹配分组数据的dtype (GH 19200)在
DataFrame.groupby()中存在一个错误,在传递on=关键字参数后,随即使用.apply()(GH 17813)在
DataFrame.resample().aggregate中存在一个错误,当聚合不存在的列时未引发KeyError(GH 16766, GH 19566)在
DataFrameGroupBy.cumsum()和DataFrameGroupBy.cumprod()中存在一个错误,当传递skipna时 (GH 19806)在
DataFrame.resample()中存在一个错误,它丢失了时区信息 (GH 13238)在
DataFrame.groupby()中存在一个错误,使用np.all和np.any进行转换时引发了ValueError(GH 20653)在
DataFrame.resample()中存在一个错误,ffill、bfill、pad、backfill、fillna、interpolate和asfreq忽略了loffset。 (GH 20744)在
DataFrame.groupby()中存在一个错误,当应用一个包含混合数据类型的函数,并且用户提供的函数可能在分组列上失败时 (GH 20949)在
DataFrameGroupBy.rolling().apply()中存在一个错误,针对关联的DataFrameGroupBy对象执行的操作可能会影响分组项在结果中的包含 (GH 14013)
稀疏#
重塑#
在
DataFrame.merge()中存在一个错误,通过名称引用CategoricalIndex时,by关键字参数会引发KeyError(GH 20777)在
DataFrame.stack()中存在一个错误,它在 Python 3 下尝试对混合类型级别进行排序时失败 (GH 18310)在
DataFrame.unstack()中存在一个错误,如果columns是一个包含未使用级别的MultiIndex,则将整数转换为浮点数 (GH 17845)在
DataFrame.unstack()中存在一个错误,如果index是一个MultiIndex,且在 unstack 级别上存在未使用的标签,则会引发错误 (GH 18562)禁用了当 len(index) > len(data) = 1 时构建
Series,之前会广播数据项,现在会引发ValueError(GH 18819)抑制了从包含标量值的
dict构建DataFrame时,当传入的索引中不包含相应的键时出现的错误 (GH 18600)修复了初始化时带有轴、无数据且
dtype=int的DataFrame的 dtype(从object更改为float64) (GH 19646)在
Series.rank()中存在一个错误,包含NaT的Series会就地修改Series(GH 18521)在
DataFrame.pivot_table()中存在一个错误,当aggfunc参数为字符串类型时失败。其行为现在与其他方法(如agg和apply)一致 (GH 18713)在
DataFrame.merge()中存在一个错误,使用Index对象作为向量进行合并时引发异常 (GH 19038)在
DataFrame.stack()、DataFrame.unstack()、Series.unstack()中存在一个错误,它们未返回子类 (GH 15563)时区比较中存在一个错误,表现为在
.concat()中索引转换为 UTC (GH 18523)在
concat()中存在一个错误,当拼接稀疏和密集序列时,它只返回一个SparseDataFrame。应该是一个DataFrame。 (GH 18914, GH 18686, 和 GH 16874)改进了
DataFrame.merge()的错误消息,当没有共同的合并键时 (GH 19427)在
DataFrame.join()中存在一个错误,当使用多个 DataFrame 调用时,如果其中一些具有非唯一索引,则执行outer连接而不是left连接 (GH 19624)Series.rename()现在接受axis作为关键字参数 (GH 18589)在
rename()中存在一个错误,其中相同长度元组的 Index 被转换为 MultiIndex (GH 19497)Series和Index之间的比较将返回一个名称不正确的Series,忽略了Index的名称属性 (GH 19582)在
qcut()中存在一个错误,存在NaT的日期时间(datetime)和时间差(timedelta)数据会引发ValueError(GH 19768)在
DataFrame.iterrows()中存在一个错误,它会将不符合 ISO8601 的字符串推断为日期时间 (GH 19671)在
Series构造函数中存在一个错误,当给定不同长度的索引时,不会引发Categorical的ValueError(GH 19342)在
DataFrame.astype()中存在一个错误,转换为分类或dtypes字典时,列元数据丢失 (GH 19920)在
Series构造函数中存在一个错误,使用dtype=str时,之前在某些情况下会引发错误 (GH 19853)在
get_dummies()和select_dtypes()中存在一个错误,重复的列名导致不正确的行为 (GH 20848)在
concat()中存在一个错误,当拼接 TZ-aware(时区感知)DataFrame和全NaT DataFrame时引发错误 (GH 12396)
其他#
改进了尝试在 `numexpr` 支持的查询中使用 Python 关键字作为标识符时的错误消息 (GH 18221)
在访问
pandas.get_option()时存在一个错误,在某些情况下查询不存在的选项键时,引发了KeyError而不是OptionError(GH 19789)在
testing.assert_series_equal()和testing.assert_frame_equal()中存在一个错误,针对具有不同 Unicode 数据的 Series 或 DataFrame 时 (GH 20503)
贡献者#
共有328人为此版本贡献了补丁。名字旁带有“+”的人是首次贡献补丁。
Aaron Critchley
AbdealiJK +
Adam Hooper +
Albert Villanova del Moral
Alejandro Giacometti +
Alejandro Hohmann +
Alex Rychyk
Alexander Buchkovsky
Alexander Lenail +
Alexander Michael Schade
Aly Sivji +
Andreas Költringer +
Andrew
Andrew Bui +
András Novoszáth +
Andy Craze +
Andy R. Terrel
Anh Le +
Anil Kumar Pallekonda +
Antoine Pitrou +
Antonio Linde +
Antonio Molina +
Antonio Quinonez +
Armin Varshokar +
Artem Bogachev +
Avi Sen +
Azeez Oluwafemi +
Ben Auffarth +
Bernhard Thiel +
Bhavesh Poddar +
BielStela +
Blair +
Bob Haffner
Brett Naul +
Brock Mendel
Bryce Guinta +
Carlos Eduardo Moreira dos Santos +
Carlos García Márquez +
Carol Willing
Cheuk Ting Ho +
Chitrank Dixit +
Chris
Chris Burr +
Chris Catalfo +
Chris Mazzullo
Christian Chwala +
Cihan Ceyhan +
Clemens Brunner
Colin +
Cornelius Riemenschneider
Crystal Gong +
DaanVanHauwermeiren
Dan Dixey +
Daniel Frank +
Daniel Garrido +
Daniel Sakuma +
DataOmbudsman +
Dave Hirschfeld
Dave Lewis +
David Adrián Cañones Castellano +
David Arcos +
David C Hall +
David Fischer
David Hoese +
David Lutz +
David Polo +
David Stansby
Dennis Kamau +
Dillon Niederhut
Dimitri +
Dr. Irv
Dror Atariah
Eric Chea +
Eric Kisslinger
Eric O. LEBIGOT (EOL) +
FAN-GOD +
Fabian Retkowski +
Fer Sar +
Gabriel de Maeztu +
Gianpaolo Macario +
Giftlin Rajaiah
Gilberto Olimpio +
Gina +
Gjelt +
Graham Inggs +
Grant Roch
Grant Smith +
Grzegorz Konefał +
Guilherme Beltramini
HagaiHargil +
Hamish Pitkeathly +
Hammad Mashkoor +
Hannah Ferchland +
Hans
Haochen Wu +
Hissashi Rocha +
Iain Barr +
Ibrahim Sharaf ElDen +
Ignasi Fosch +
Igor Conrado Alves de Lima +
Igor Shelvinskyi +
Imanflow +
Ingolf Becker
Israel Saeta Pérez
Iva Koevska +
Jakub Nowacki +
Jan F-F +
Jan Koch +
Jan Werkmann
Janelle Zoutkamp +
Jason Bandlow +
Jaume Bonet +
Jay Alammar +
Jeff Reback
JennaVergeynst
Jimmy Woo +
Jing Qiang Goh +
Joachim Wagner +
Joan Martin Miralles +
Joel Nothman
Joeun Park +
John Cant +
Johnny Metz +
Jon Mease
Jonas Schulze +
Jongwony +
Jordi Contestí +
Joris Van den Bossche
José F. R. Fonseca +
Jovixe +
Julio Martinez +
Jörg Döpfert
KOBAYASHI Ittoku +
Kate Surta +
Kenneth +
Kevin Kuhl
Kevin Sheppard
Krzysztof Chomski
Ksenia +
Ksenia Bobrova +
Kunal Gosar +
Kurtis Kerstein +
Kyle Barron +
Laksh Arora +
Laurens Geffert +
Leif Walsh
Liam Marshall +
Liam3851 +
Licht Takeuchi
Liudmila +
Ludovico Russo +
Mabel Villalba +
Manan Pal Singh +
Manraj Singh
Marc +
Marc Garcia
Marco Hemken +
Maria del Mar Bibiloni +
Mario Corchero +
Mark Woodbridge +
Martin Journois +
Mason Gallo +
Matias Heikkilä +
Matt Braymer-Hayes
Matt Kirk +
Matt Maybeno +
Matthew Kirk +
Matthew Rocklin +
Matthew Roeschke
Matthias Bussonnier +
Max Mikhaylov +
Maxim Veksler +
Maximilian Roos
Maximiliano Greco +
Michael Penkov
Michael Röttger +
Michael Selik +
Michael Waskom
Mie~~~
Mike Kutzma +
Ming Li +
Mitar +
Mitch Negus +
Montana Low +
Moritz Münst +
Mortada Mehyar
Myles Braithwaite +
Nate Yoder
Nicholas Ursa +
Nick Chmura
Nikos Karagiannakis +
Nipun Sadvilkar +
Nis Martensen +
Noah +
Noémi Éltető +
Olivier Bilodeau +
Ondrej Kokes +
Onno Eberhard +
Paul Ganssle +
Paul Mannino +
Paul Reidy
Paulo Roberto de Oliveira Castro +
Pepe Flores +
Peter Hoffmann
Phil Ngo +
Pietro Battiston
Pranav Suri +
Priyanka Ojha +
Pulkit Maloo +
README Bot +
Ray Bell +
Riccardo Magliocchetti +
Ridhwan Luthra +
Robert Meyer
Robin
Robin Kiplang’at +
Rohan Pandit +
Rok Mihevc +
Rouz Azari
Ryszard T. Kaleta +
Sam Cohan
Sam Foo
Samir Musali +
Samuel Sinayoko +
Sangwoong Yoon
SarahJessica +
Sharad Vijalapuram +
Shubham Chaudhary +
SiYoungOh +
Sietse Brouwer
Simone Basso +
Stefania Delprete +
Stefano Cianciulli +
Stephen Childs +
StephenVoland +
Stijn Van Hoey +
Sven
Talitha Pumar +
Tarbo Fukazawa +
Ted Petrou +
Thomas A Caswell
Tim Hoffmann +
Tim Swast
Tom Augspurger
Tommy +
Tulio Casagrande +
Tushar Gupta +
Tushar Mittal +
Upkar Lidder +
Victor Villas +
Vince W +
Vinícius Figueiredo +
Vipin Kumar +
WBare
Wenhuan +
Wes Turner
William Ayd
Wilson Lin +
Xbar
Yaroslav Halchenko
Yee Mey
Yeongseon Choe +
Yian +
Yimeng Zhang
ZhuBaohe +
Zihao Zhao +
adatasetaday +
akielbowicz +
akosel +
alinde1 +
amuta +
bolkedebruin
cbertinato
cgohlke
charlie0389 +
chris-b1
csfarkas +
dajcs +
deflatSOCO +
derestle-htwg
discort
dmanikowski-reef +
donK23 +
elrubio +
fivemok +
fjdiod
fjetter +
froessler +
gabrielclow
gfyoung
ghasemnaddaf
h-vetinari +
himanshu awasthi +
ignamv +
jayfoad +
jazzmuesli +
jbrockmendel
jen w +
jjames34 +
joaoavf +
joders +
jschendel
juan huguet +
l736x +
luzpaz +
mdeboc +
miguelmorin +
miker985
miquelcamprodon +
orereta +
ottiP +
peterpanmj +
rafarui +
raph-m +
readyready15728 +
rmihael +
samghelms +
scriptomation +
sfoo +
stefansimik +
stonebig
tmnhat2001 +
tomneep +
topper-123
tv3141 +
verakai +
xpvpc +
zhanghui +