In [1]: import pandas as pd
- 泰坦尼克号数据
本教程使用泰坦尼克号数据集,该数据集以 CSV 格式存储。数据包含以下数据列:
PassengerId: 每位乘客的 ID。
Survived: 表明乘客是否幸存。
0表示是,1表示否。Pclass: 3 种船票等级之一:
1等舱,2等舱和3等舱。Name: 乘客姓名。
Sex: 乘客性别。
Age: 乘客年龄(以年为单位)。
SibSp: 船上兄弟姐妹或配偶的数量。
Parch: 船上父母或子女的数量。
Ticket: 乘客票号。
Fare: 票价。
Cabin: 乘客客舱号。
Embarked: 登船港口。
In [2]: titanic = pd.read_csv("data/titanic.csv") In [3]: titanic.head() Out[3]: PassengerId Survived Pclass ... Fare Cabin Embarked 0 1 0 3 ... 7.2500 NaN S 1 2 1 1 ... 71.2833 C85 C 2 3 1 3 ... 7.9250 NaN S 3 4 1 1 ... 53.1000 C123 S 4 5 0 3 ... 8.0500 NaN S [5 rows x 12 columns]
-
空气质量数据
本教程使用关于 \(NO_2\) 和小于 2.5 微米颗粒物的空气质量数据,这些数据由 OpenAQ 提供并使用 py-openaq 包。
air_quality_long.csv数据集分别提供了巴黎、安特卫普和伦敦测量站 FR04014、BETR801 和 London Westminster 的 \(NO_2\) 和 \(PM_{25}\) 值。空气质量数据集包含以下列:
city: 传感器所在的城市,可以是巴黎、安特卫普或伦敦
country: 传感器所在的国家,可以是法国 (FR)、比利时 (BE) 或英国 (GB)
location: 传感器的 ID,可以是 FR04014、BETR801 或 London Westminster
parameter: 传感器测量的参数,可以是 \(NO_2\) 或颗粒物
value: 测量值
unit: 测量参数的单位,本例中为“µg/m³”
并且
DataFrame的索引是datetime,即测量的日期时间。前往原始数据注意
空气质量数据以所谓的长格式数据表示形式提供,其中每个观测值占据一个单独的行,每个变量占据数据表的一个单独的列。长/窄格式也称为整洁数据格式。
In [4]: air_quality = pd.read_csv( ...: "data/air_quality_long.csv", index_col="date.utc", parse_dates=True ...: ) ...: In [5]: air_quality.head() Out[5]: city country location parameter value unit date.utc 2019-06-18 06:00:00+00:00 Antwerpen BE BETR801 pm25 18.0 µg/m³ 2019-06-17 08:00:00+00:00 Antwerpen BE BETR801 pm25 6.5 µg/m³ 2019-06-17 07:00:00+00:00 Antwerpen BE BETR801 pm25 18.5 µg/m³ 2019-06-17 06:00:00+00:00 Antwerpen BE BETR801 pm25 16.0 µg/m³ 2019-06-17 05:00:00+00:00 Antwerpen BE BETR801 pm25 7.5 µg/m³
如何重塑表格布局#
排序表格行#
我想根据乘客的年龄对泰坦尼克号数据进行排序。
In [6]: titanic.sort_values(by="Age").head() Out[6]: PassengerId Survived Pclass ... Fare Cabin Embarked 803 804 1 3 ... 8.5167 NaN C 755 756 1 2 ... 14.5000 NaN S 644 645 1 3 ... 19.2583 NaN C 469 470 1 3 ... 19.2583 NaN C 78 79 1 2 ... 29.0000 NaN S [5 rows x 12 columns]
我想根据客舱等级和年龄以降序排列泰坦尼克号数据。
In [7]: titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head() Out[7]: PassengerId Survived Pclass ... Fare Cabin Embarked 851 852 0 3 ... 7.7750 NaN S 116 117 0 3 ... 7.7500 NaN Q 280 281 0 3 ... 7.7500 NaN Q 483 484 1 3 ... 9.5875 NaN S 326 327 0 3 ... 6.2375 NaN S [5 rows x 12 columns]
使用
DataFrame.sort_values(),表格中的行会根据定义的列进行排序。索引将跟随行的顺序。
有关表格排序的更多详细信息,请参阅用户指南的数据排序部分。
长格式到宽格式表#
让我们使用空气质量数据集的一个小 F子集。我们关注 \(NO_2\) 数据,并且只使用每个位置的前两次测量(即每个组的头部)。这个数据子集将被称为 no2_subset。
# filter for no2 data only
In [8]: no2 = air_quality[air_quality["parameter"] == "no2"]
# use 2 measurements (head) for each location (groupby)
In [9]: no2_subset = no2.sort_index().groupby(["location"]).head(2)
In [10]: no2_subset
Out[10]:
city country ... value unit
date.utc ...
2019-04-09 01:00:00+00:00 Antwerpen BE ... 22.5 µg/m³
2019-04-09 01:00:00+00:00 Paris FR ... 24.4 µg/m³
2019-04-09 02:00:00+00:00 London GB ... 67.0 µg/m³
2019-04-09 02:00:00+00:00 Antwerpen BE ... 53.5 µg/m³
2019-04-09 02:00:00+00:00 Paris FR ... 27.4 µg/m³
2019-04-09 03:00:00+00:00 London GB ... 67.0 µg/m³
[6 rows x 6 columns]

我希望将三个测量站的值作为单独的列并排显示。
In [11]: no2_subset.pivot(columns="location", values="value") Out[11]: location BETR801 FR04014 London Westminster date.utc 2019-04-09 01:00:00+00:00 22.5 24.4 NaN 2019-04-09 02:00:00+00:00 53.5 27.4 67.0 2019-04-09 03:00:00+00:00 NaN NaN 67.0
pivot()函数纯粹是对数据进行重塑:每个索引/列组合都需要一个单一的值。
由于 pandas 原生支持多列绘图(参见绘图教程),因此从长格式到宽格式的表格转换使得可以同时绘制不同的时间序列。
In [12]: no2.head()
Out[12]:
city country location parameter value unit
date.utc
2019-06-21 00:00:00+00:00 Paris FR FR04014 no2 20.0 µg/m³
2019-06-20 23:00:00+00:00 Paris FR FR04014 no2 21.8 µg/m³
2019-06-20 22:00:00+00:00 Paris FR FR04014 no2 26.5 µg/m³
2019-06-20 21:00:00+00:00 Paris FR FR04014 no2 24.9 µg/m³
2019-06-20 20:00:00+00:00 Paris FR FR04014 no2 21.4 µg/m³
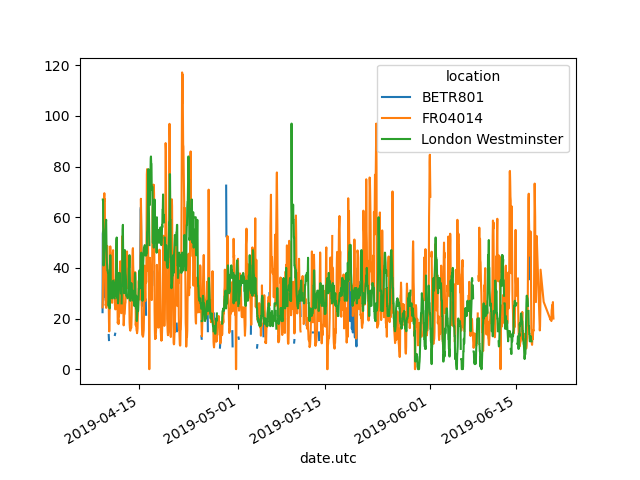
In [13]: no2.pivot(columns="location", values="value").plot()
Out[13]: <Axes: xlabel='date.utc'>
注意
如果未定义 index 参数,则使用现有索引(行标签)。
有关 pivot() 的更多信息,请参阅用户指南中关于透视 DataFrame 对象的部分。
数据透视表#

我希望以表格形式显示每个测量站的 \(NO_2\) 和 \(PM_{2.5}\) 平均浓度。
In [14]: air_quality.pivot_table( ....: values="value", index="location", columns="parameter", aggfunc="mean" ....: ) ....: Out[14]: parameter no2 pm25 location BETR801 26.950920 23.169492 FR04014 29.374284 NaN London Westminster 29.740050 13.443568
对于
pivot(),数据只是被重新排列。当需要聚合多个值时(在本例中,是不同时间步长的值),可以使用pivot_table(),它提供一个聚合函数(例如平均值)来组合这些值。
数据透视表是电子表格软件中一个众所周知的概念。当您对每个变量的行/列边距(小计)感兴趣时,请将 margins 参数设置为 True。
In [15]: air_quality.pivot_table(
....: values="value",
....: index="location",
....: columns="parameter",
....: aggfunc="mean",
....: margins=True,
....: )
....:
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743
有关 pivot_table() 的更多信息,请参阅用户指南中关于数据透视表的部分。
注意
如果您想知道,pivot_table() 确实与 groupby() 直接相关。通过同时对 parameter 和 location 进行分组,可以得到相同的结果。
air_quality.groupby(["parameter", "location"])[["value"]].mean()
宽格式到长格式#
从上一节创建的宽格式表开始,我们使用 reset_index() 为 DataFrame 添加一个新的索引。
In [16]: no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
In [17]: no2_pivoted.head()
Out[17]:
location date.utc BETR801 FR04014 London Westminster
0 2019-04-09 01:00:00+00:00 22.5 24.4 NaN
1 2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2 2019-04-09 03:00:00+00:00 54.5 34.2 67.0
3 2019-04-09 04:00:00+00:00 34.5 48.5 41.0
4 2019-04-09 05:00:00+00:00 46.5 59.5 41.0

我想将所有空气质量 \(NO_2\) 测量值收集到一个单独的列中(长格式)。
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc") In [19]: no_2.head() Out[19]: date.utc location value 0 2019-04-09 01:00:00+00:00 BETR801 22.5 1 2019-04-09 02:00:00+00:00 BETR801 53.5 2 2019-04-09 03:00:00+00:00 BETR801 54.5 3 2019-04-09 04:00:00+00:00 BETR801 34.5 4 2019-04-09 05:00:00+00:00 BETR801 46.5
在
DataFrame上使用pandas.melt()方法可以将数据表从宽格式转换为长格式。列标题会成为新创建列中的变量名。
这个解决方案是应用 pandas.melt() 的简短版本。该方法将把所有未在 id_vars 中提及的列“熔化”成两列:一列包含列标题名称,另一列包含值本身。后一列默认名为 value。
传递给 pandas.melt() 的参数可以更详细地定义:
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
....:
In [21]: no_2.head()
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5
附加参数具有以下效果:
value_vars定义要一起熔化的列value_name为值列提供自定义列名,而不是默认列名valuevar_name为收集列标题名称的列提供自定义列名。否则,它将采用索引名称或默认的variable。
因此,参数 value_name 和 var_name 只是为生成的两列提供的用户定义名称。要熔化的列由 id_vars 和 value_vars 定义。
使用 pandas.melt() 从宽格式到长格式的转换在用户指南的通过 melt 重塑部分中进行了说明。
请记住
通过
sort_values支持按一列或多列排序。pivot函数纯粹是对数据进行重构,而pivot_table支持聚合。pivot(长格式到宽格式)的反向操作是melt(宽格式到长格式)。
完整的概述可在用户指南的重塑与透视页面中找到。