图表可视化#
注意
以下示例假设您正在使用 Jupyter。
本节演示了通过图表进行可视化。有关表格数据的可视化信息,请参阅表格可视化一节。
我们使用标准的约定来引用 Matplotlib API
In [1]: import matplotlib.pyplot as plt
In [2]: plt.close("all")
我们在 pandas 中提供了基础功能,以便轻松创建外观不错的图表。有关超出本文档基础功能的其他可视化库,请参阅生态系统页面。
注意
np.random 的所有调用都使用 123456 作为种子。
基本绘图:plot#
我们将演示基础知识,有关高级策略,请参阅实用代码片段。
Series 和 DataFrame 上的 plot 方法只是 plt.plot() 的一个简单包装器。
In [3]: np.random.seed(123456)
In [4]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [5]: ts = ts.cumsum()
In [6]: ts.plot();
如果索引包含日期,它会调用 gcf().autofmt_xdate() 来尝试按上述方式美化 x 轴的格式。
在 DataFrame 上,plot() 是一个方便的方法,用于绘制所有带标签的列。
In [7]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [8]: df = df.cumsum()
In [9]: plt.figure();
In [10]: df.plot();
您可以使用 plot() 中的 x 和 y 关键字来绘制一列与另一列的关系。
In [11]: df3 = pd.DataFrame(np.random.randn(1000, 2), columns=["B", "C"]).cumsum()
In [12]: df3["A"] = pd.Series(list(range(len(df))))
In [13]: df3.plot(x="A", y="B");
注意
有关更多格式和样式选项,请参阅下面的格式化。
其他图表#
绘图方法除了默认的折线图之外,还支持多种绘图样式。这些方法可以通过 plot() 的 kind 关键字参数提供,包括:
例如,条形图可以通过以下方式创建:
In [14]: plt.figure();
In [15]: df.iloc[5].plot(kind="bar");
您也可以使用 DataFrame.plot.<kind> 方法来创建这些其他图表,而不是提供 kind 关键字参数。这使得发现绘图方法及其特定参数变得更容易。
In [16]: df = pd.DataFrame()
In [17]: df.plot.<TAB> # noqa: E225, E999
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
除了这些 kind 之外,还有 DataFrame.hist() 和 DataFrame.boxplot() 方法,它们使用单独的接口。
最后,pandas.plotting 中有几个绘图函数,它们接受 Series 或 DataFrame 作为参数。这些包括:
条形图#
对于带标签的非时间序列数据,您可能希望生成条形图。
In [18]: plt.figure();
In [19]: df.iloc[5].plot.bar();
In [20]: plt.axhline(0, color="k");
调用 DataFrame 的 plot.bar() 方法会生成一个多条形图。
In [21]: df2 = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
In [22]: df2.plot.bar();
要生成堆叠条形图,请传递 stacked=True。
In [23]: df2.plot.bar(stacked=True);
要获取水平条形图,请使用 barh 方法。
In [24]: df2.plot.barh(stacked=True);
直方图#
可以使用 DataFrame.plot.hist() 和 Series.plot.hist() 方法绘制直方图。
In [25]: df4 = pd.DataFrame(
....: {
....: "a": np.random.randn(1000) + 1,
....: "b": np.random.randn(1000),
....: "c": np.random.randn(1000) - 1,
....: },
....: columns=["a", "b", "c"],
....: )
....:
In [26]: plt.figure();
In [27]: df4.plot.hist(alpha=0.5);
直方图可以使用 stacked=True 进行堆叠。可以通过 bins 关键字更改分箱大小。
In [28]: plt.figure();
In [29]: df4.plot.hist(stacked=True, bins=20);
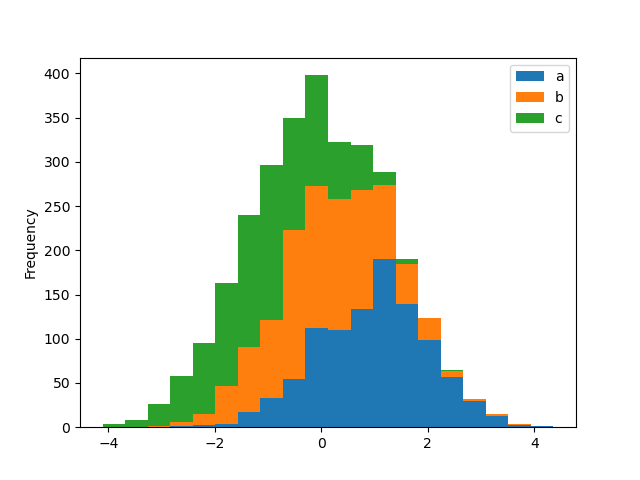
您可以传递 matplotlib hist 支持的其他关键字。例如,水平和累积直方图可以通过 orientation='horizontal' 和 cumulative=True 绘制。
In [30]: plt.figure();
In [31]: df4["a"].plot.hist(orientation="horizontal", cumulative=True);
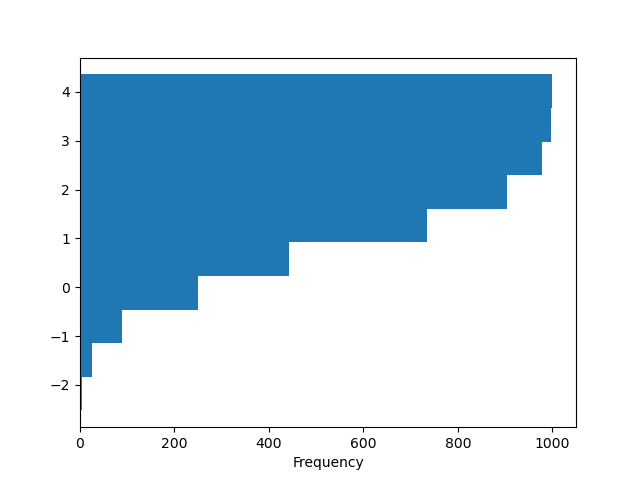
有关更多信息,请参阅 hist 方法和 matplotlib hist 文档。
绘制直方图的现有接口 DataFrame.hist 仍然可以使用。
In [32]: plt.figure();
In [33]: df["A"].diff().hist();
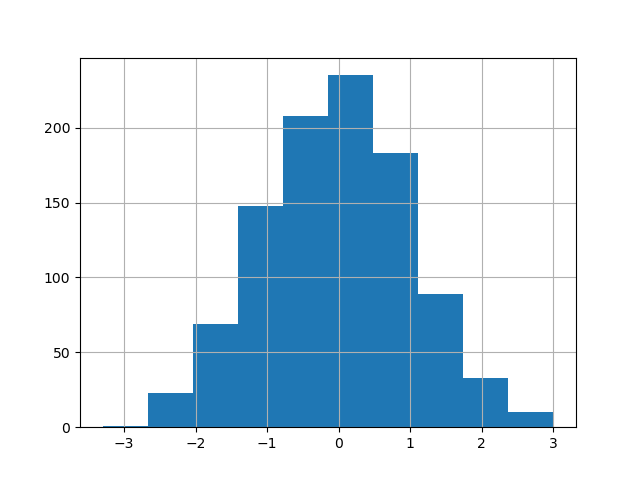
DataFrame.hist() 在多个子图上绘制列的直方图。
In [34]: plt.figure();
In [35]: df.diff().hist(color="k", alpha=0.5, bins=50);
可以指定 by 关键字来绘制分组直方图。
In [36]: data = pd.Series(np.random.randn(1000))
In [37]: data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4));
此外,by 关键字也可以在 DataFrame.plot.hist() 中指定。
1.4.0 版本新增。
In [38]: data = pd.DataFrame(
....: {
....: "a": np.random.choice(["x", "y", "z"], 1000),
....: "b": np.random.choice(["e", "f", "g"], 1000),
....: "c": np.random.randn(1000),
....: "d": np.random.randn(1000) - 1,
....: },
....: )
....:
In [39]: data.plot.hist(by=["a", "b"], figsize=(10, 5));
箱线图#
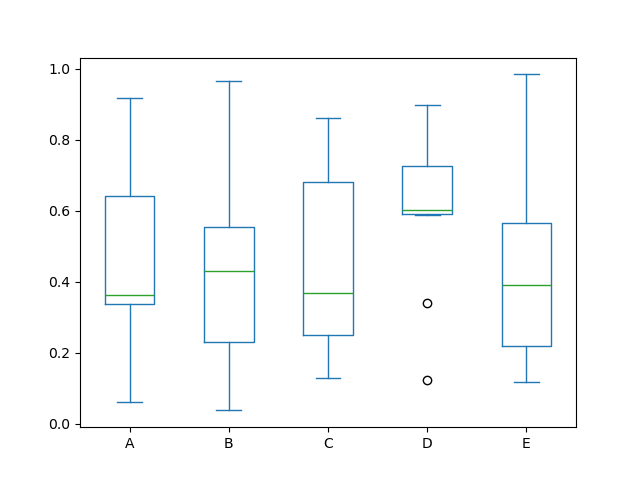
可以通过调用 Series.plot.box() 和 DataFrame.plot.box(),或者 DataFrame.boxplot() 来绘制箱线图,以可视化每列中值的分布。
例如,这是一个箱线图,表示在 [0,1) 上均匀随机变量的 10 次观测的五次试验。
In [40]: df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
In [41]: df.plot.box();
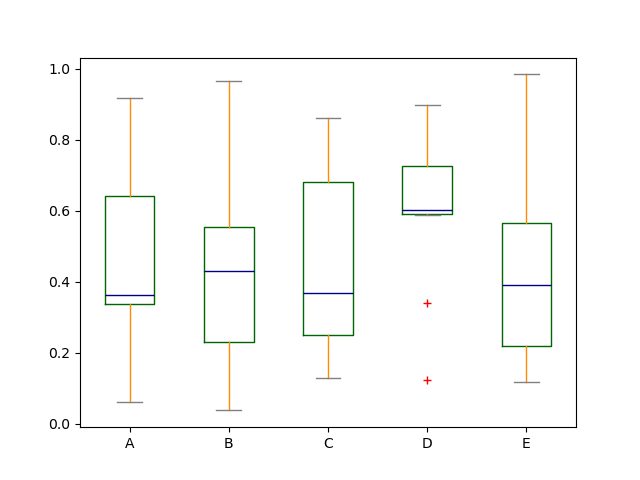
箱线图可以通过传递 color 关键字进行着色。您可以传递一个 dict,其键为 boxes、whiskers、medians 和 caps。如果 dict 中缺少某些键,则使用默认颜色对应艺术家。此外,箱线图还有 sym 关键字来指定异常值样式。
当您通过 color 关键字传递其他类型的参数时,它将直接传递给 Matplotlib,用于所有 boxes、whiskers、medians 和 caps 的着色。
颜色将应用于所有绘制的箱体。如果您想要更复杂的着色,可以通过传递 return_type 获取每个绘制的艺术家。
In [42]: color = {
....: "boxes": "DarkGreen",
....: "whiskers": "DarkOrange",
....: "medians": "DarkBlue",
....: "caps": "Gray",
....: }
....:
In [43]: df.plot.box(color=color, sym="r+");
此外,您还可以传递 Matplotlib boxplot 支持的其他关键字。例如,水平和自定义位置的箱线图可以通过 vert=False 和 positions 关键字绘制。
In [44]: df.plot.box(vert=False, positions=[1, 4, 5, 6, 8]);
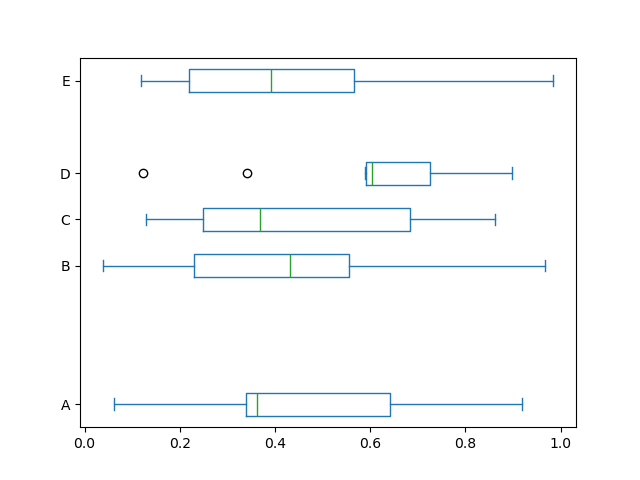
有关更多信息,请参阅 boxplot 方法和 matplotlib boxplot 文档。
绘制箱线图的现有接口 DataFrame.boxplot 仍然可以使用。
In [45]: df = pd.DataFrame(np.random.rand(10, 5))
In [46]: plt.figure();
In [47]: bp = df.boxplot()
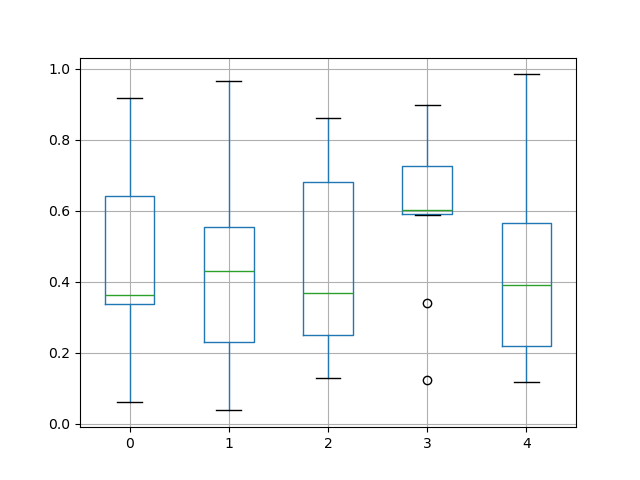
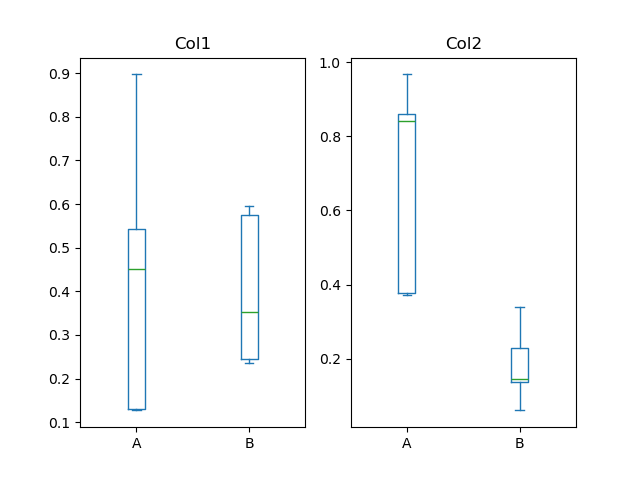
您可以使用 by 关键字参数创建分层箱线图来创建分组。例如,
In [48]: df = pd.DataFrame(np.random.rand(10, 2), columns=["Col1", "Col2"])
In [49]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [50]: plt.figure();
In [51]: bp = df.boxplot(by="X")
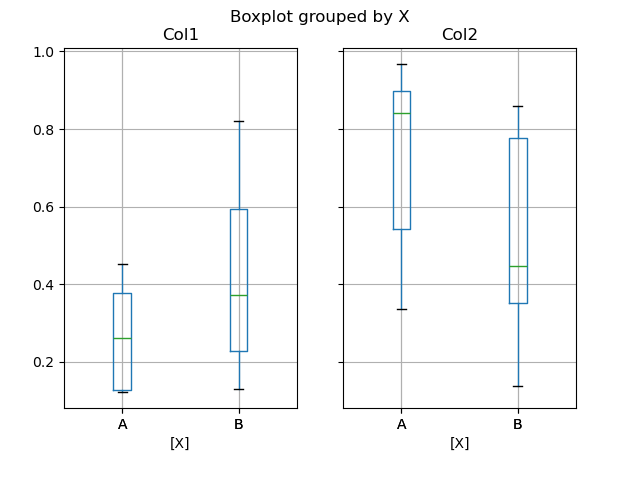
您也可以传递要绘制的列的子集,以及按多列分组。
In [52]: df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"])
In [53]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [54]: df["Y"] = pd.Series(["A", "B", "A", "B", "A", "B", "A", "B", "A", "B"])
In [55]: plt.figure();
In [56]: bp = df.boxplot(column=["Col1", "Col2"], by=["X", "Y"])
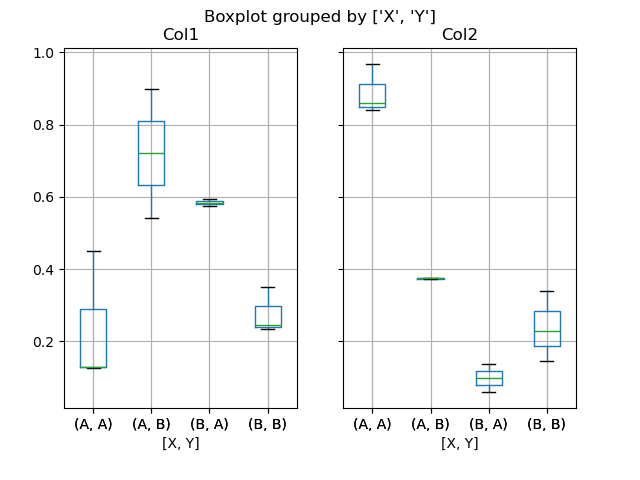
您也可以使用 DataFrame.plot.box() 创建分组,例如:
1.4.0 版本新增。
In [57]: df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"])
In [58]: df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"])
In [59]: plt.figure();
In [60]: bp = df.plot.box(column=["Col1", "Col2"], by="X")
在 boxplot 中,返回类型可以通过 return_type 关键字控制。有效选项为 {"axes", "dict", "both", None}。由 DataFrame.boxplot 与 by 关键字创建的分面也会影响输出类型。
|
分面 |
输出类型 |
|---|---|---|
|
否 |
轴 |
|
是 |
2D 轴数组 |
|
否 |
轴 |
|
是 |
轴的 Series |
|
否 |
艺术家的 dict |
|
是 |
艺术家的 dict 的 Series |
|
否 |
命名元组 |
|
是 |
命名元组的 Series |
Groupby.boxplot 总是返回一个 return_type 的 Series。
In [61]: np.random.seed(1234)
In [62]: df_box = pd.DataFrame(np.random.randn(50, 2))
In [63]: df_box["g"] = np.random.choice(["A", "B"], size=50)
In [64]: df_box.loc[df_box["g"] == "B", 1] += 3
In [65]: bp = df_box.boxplot(by="g")
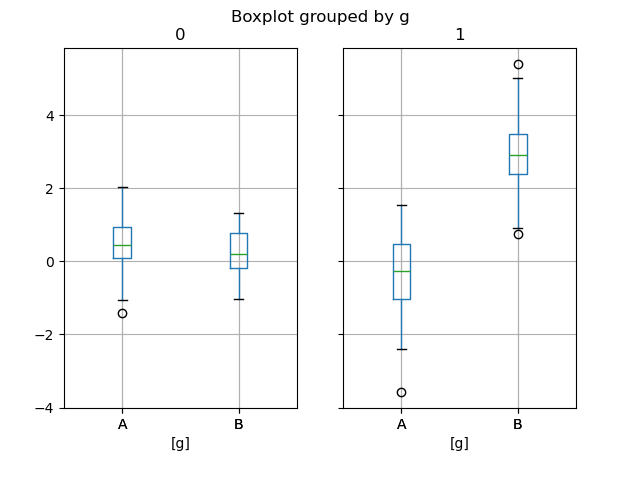
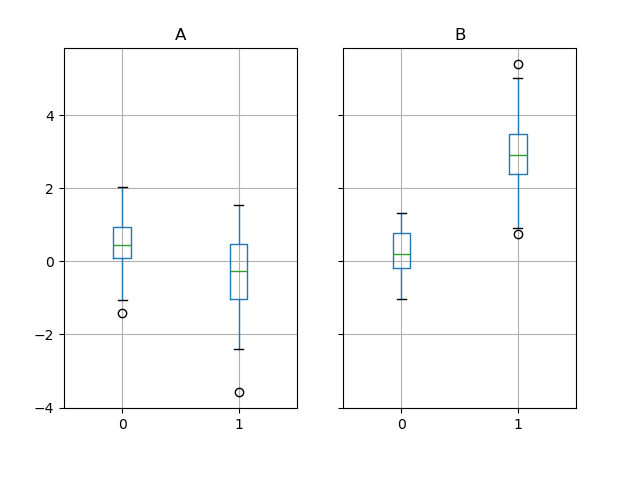
上面的子图首先按数值列分割,然后按 g 列的值分割。下面的子图首先按 g 的值分割,然后按数值列分割。
In [66]: bp = df_box.groupby("g").boxplot()
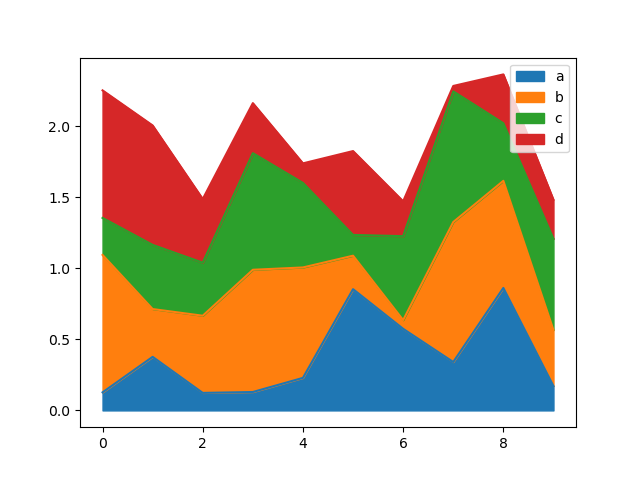
面积图#
您可以使用 Series.plot.area() 和 DataFrame.plot.area() 创建面积图。面积图默认是堆叠的。要生成堆叠面积图,每列的值必须都是正数或都是负数。
当输入数据包含 NaN 时,它将自动填充为 0。如果您想丢弃或用不同值填充,请在调用 plot 之前使用 dataframe.dropna() 或 dataframe.fillna()。
In [67]: df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
In [68]: df.plot.area();
要生成非堆叠图,请传递 stacked=False。Alpha 值默认为 0.5,除非另有指定。
In [69]: df.plot.area(stacked=False);
散点图#
散点图可以使用 DataFrame.plot.scatter() 方法绘制。散点图需要用于 x 轴和 y 轴的数值列。这些可以通过 x 和 y 关键字指定。
In [70]: df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"])
In [71]: df["species"] = pd.Categorical(
....: ["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10
....: )
....:
In [72]: df.plot.scatter(x="a", y="b");
要在单个轴中绘制多个列组,请重复 plot 方法并指定目标 ax。建议指定 color 和 label 关键字以区分每个组。
In [73]: ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1")
In [74]: df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax);
关键字 c 可以指定为列的名称,以提供每个点的颜色。
In [75]: df.plot.scatter(x="a", y="b", c="c", s=50);
如果将分类列传递给 c,则会生成一个离散的颜色条。
1.3.0 版本新增。
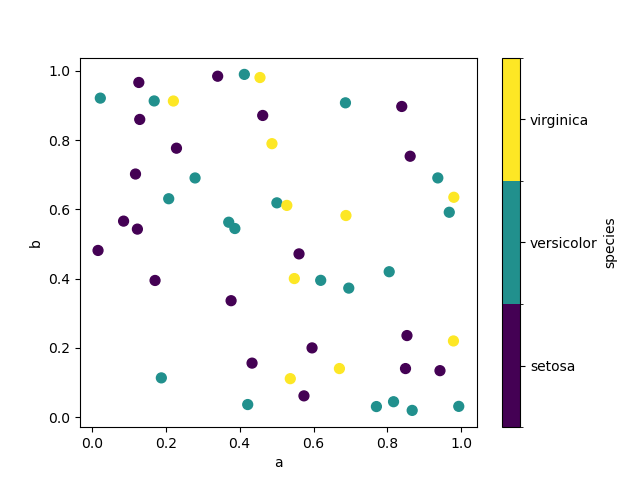
In [76]: df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50);
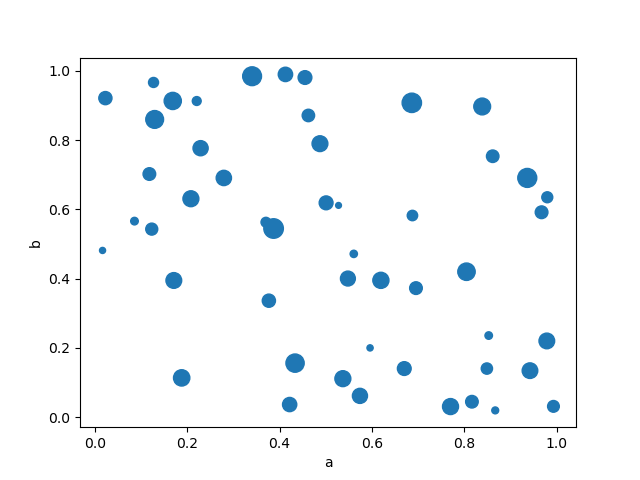
您可以传递 matplotlib scatter 支持的其他关键字。下面的示例展示了如何使用 DataFrame 的一列作为气泡大小来创建气泡图。
In [77]: df.plot.scatter(x="a", y="b", s=df["c"] * 200);
有关更多信息,请参阅 scatter 方法和 matplotlib scatter 文档。
六边形分箱图#
您可以使用 DataFrame.plot.hexbin() 创建六边形分箱图。如果您的数据过于密集,无法单独绘制每个点,六边形分箱图可以作为散点图的一个有用替代方案。
In [78]: df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
In [79]: df["b"] = df["b"] + np.arange(1000)
In [80]: df.plot.hexbin(x="a", y="b", gridsize=25);
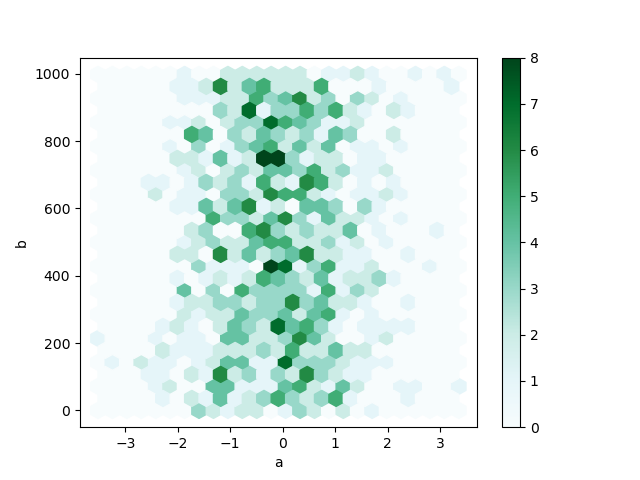
一个有用的关键字参数是 gridsize;它控制 x 方向的六边形数量,默认为 100。较大的 gridsize 意味着更多、更小的分箱。
默认情况下,计算每个 (x, y) 点周围计数的直方图。您可以通过向 C 和 reduce_C_function 参数传递值来指定替代聚合。C 指定每个 (x, y) 点的值,reduce_C_function 是一个接受一个参数的函数,它将分箱中的所有值归约为一个单一的数字(例如 mean、max、sum、std)。在此示例中,位置由列 a 和 b 给出,而值由列 z 给出。分箱使用 NumPy 的 max 函数进行聚合。
In [81]: df = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
In [82]: df["b"] = df["b"] + np.arange(1000)
In [83]: df["z"] = np.random.uniform(0, 3, 1000)
In [84]: df.plot.hexbin(x="a", y="b", C="z", reduce_C_function=np.max, gridsize=25);
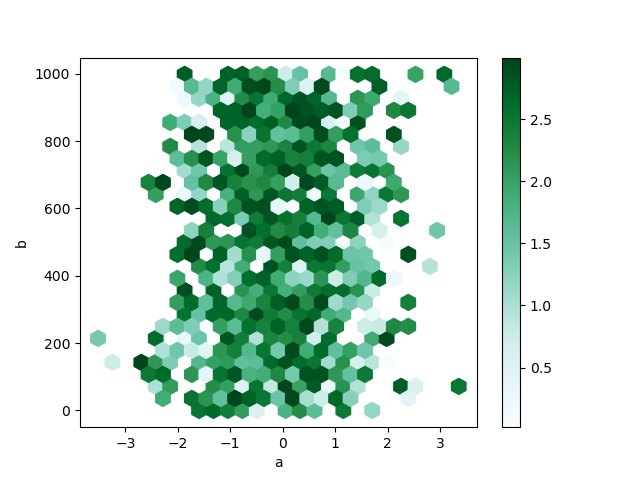
有关更多信息,请参阅 hexbin 方法和 matplotlib hexbin 文档。
饼图#
您可以使用 DataFrame.plot.pie() 或 Series.plot.pie() 创建饼图。如果您的数据包含任何 NaN,它们将自动填充为 0。如果您的数据中有任何负值,将引发 ValueError。
In [85]: series = pd.Series(3 * np.random.rand(4), index=["a", "b", "c", "d"], name="series")
In [86]: series.plot.pie(figsize=(6, 6));
对于饼图,最好使用方形图,即图的宽高比为 1。您可以创建具有相等宽度和高度的图,或者在绘制后通过在返回的 axes 对象上调用 ax.set_aspect('equal') 来强制宽高比相等。
请注意,使用 DataFrame 绘制饼图要求您要么通过 y 参数指定目标列,要么指定 subplots=True。当指定 y 时,将绘制所选列的饼图。如果指定 subplots=True,则将每列的饼图绘制为子图。默认情况下,每个饼图都会绘制图例;指定 legend=False 可将其隐藏。
In [87]: df = pd.DataFrame(
....: 3 * np.random.rand(4, 2), index=["a", "b", "c", "d"], columns=["x", "y"]
....: )
....:
In [88]: df.plot.pie(subplots=True, figsize=(8, 4));
您可以使用 labels 和 colors 关键字来指定每个扇区的标签和颜色。
警告
大多数 pandas 绘图使用 label 和 color 参数(请注意它们没有“s”)。为了与 matplotlib.pyplot.pie() 保持一致,您必须使用 labels 和 colors。
如果要隐藏扇区标签,请指定 labels=None。如果指定了 fontsize,该值将应用于扇区标签。此外,Matplotlib matplotlib.pyplot.pie() 支持的其他关键字也可以使用。
In [89]: series.plot.pie(
....: labels=["AA", "BB", "CC", "DD"],
....: colors=["r", "g", "b", "c"],
....: autopct="%.2f",
....: fontsize=20,
....: figsize=(6, 6),
....: );
....:
如果您传入的总和小于 1.0 的值,它们将被重新缩放,使其总和为 1。
In [90]: series = pd.Series([0.1] * 4, index=["a", "b", "c", "d"], name="series2")
In [91]: series.plot.pie(figsize=(6, 6));
有关更多信息,请参阅 matplotlib 饼图文档。
缺失数据绘图#
pandas 试图务实地处理包含缺失数据的 DataFrame 或 Series 绘图。缺失值根据图表类型被丢弃、忽略或填充。
图表类型 |
NaN 处理 |
|---|---|
折线图 |
在 NaN 处留出空白 |
折线图(堆叠) |
填充 0 |
条形图 |
填充 0 |
散点图 |
丢弃 NaN |
直方图 |
丢弃 NaN(按列) |
箱线图 |
丢弃 NaN(按列) |
面积图 |
填充 0 |
KDE |
丢弃 NaN(按列) |
六边形分箱图 |
丢弃 NaN |
饼图 |
填充 0 |
如果这些默认行为不符合您的需求,或者您希望明确如何处理缺失值,请考虑在绘图之前使用 fillna() 或 dropna()。
绘图工具#
这些函数可以从 pandas.plotting 导入,并接受 Series 或 DataFrame 作为参数。
散点矩阵图#
您可以使用 pandas.plotting 中的 scatter_matrix 方法创建散点图矩阵。
In [92]: from pandas.plotting import scatter_matrix
In [93]: df = pd.DataFrame(np.random.randn(1000, 4), columns=["a", "b", "c", "d"])
In [94]: scatter_matrix(df, alpha=0.2, figsize=(6, 6), diagonal="kde");
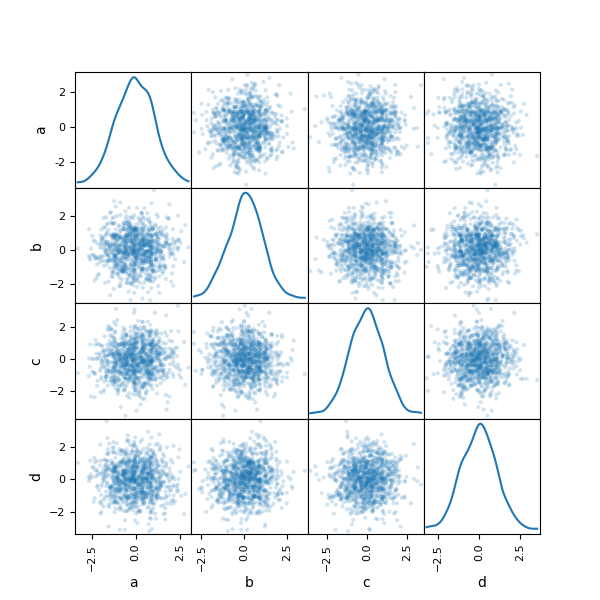
密度图#
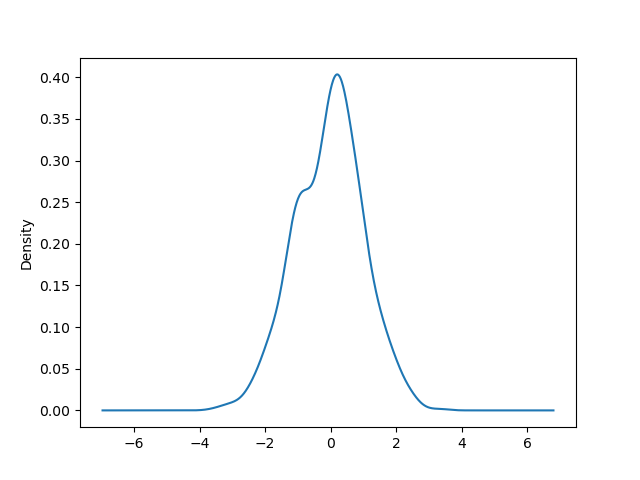
您可以使用 Series.plot.kde() 和 DataFrame.plot.kde() 方法创建密度图。
In [95]: ser = pd.Series(np.random.randn(1000))
In [96]: ser.plot.kde();
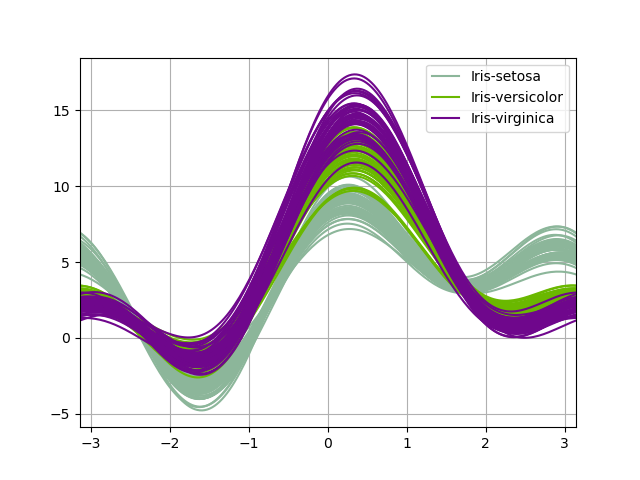
安德鲁斯曲线#
安德鲁斯曲线允许将多元数据绘制为大量曲线,这些曲线是使用样本属性作为傅里叶级数系数创建的。有关更多信息,请参阅维基百科条目。通过为每个类别着色,可以可视化数据聚类。属于同一类别的样本曲线通常会更接近并形成更大的结构。
注意:“Iris”数据集可在此处获取。
In [97]: from pandas.plotting import andrews_curves
In [98]: data = pd.read_csv("data/iris.data")
In [99]: plt.figure();
In [100]: andrews_curves(data, "Name");
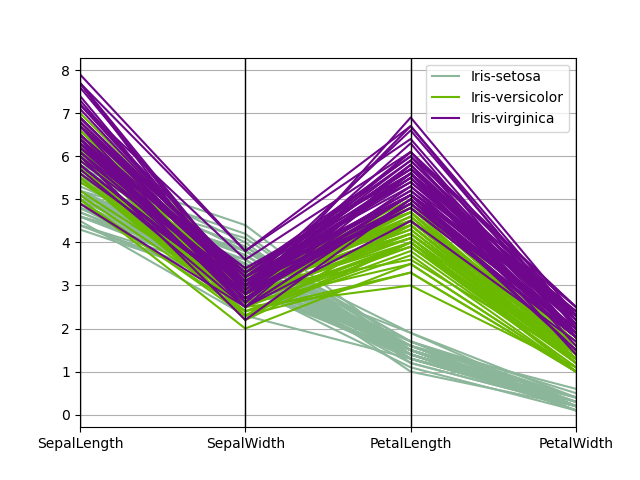
平行坐标#
平行坐标是一种绘制多元数据的绘图技术,有关介绍请参阅维基百科条目。平行坐标允许人们查看数据中的聚类并视觉估计其他统计数据。使用平行坐标时,点表示为连接的线段。每条垂直线代表一个属性。一组连接的线段代表一个数据点。倾向于聚类的点将显得更靠近。
In [101]: from pandas.plotting import parallel_coordinates
In [102]: data = pd.read_csv("data/iris.data")
In [103]: plt.figure();
In [104]: parallel_coordinates(data, "Name");
滞后图#
滞后图用于检查数据集或时间序列是否随机。随机数据在滞后图中不应显示任何结构。非随机结构意味着底层数据不是随机的。lag 参数可以传递,当 lag=1 时,该图本质上是 data[:-1] 与 data[1:] 的关系图。
In [105]: from pandas.plotting import lag_plot
In [106]: plt.figure();
In [107]: spacing = np.linspace(-99 * np.pi, 99 * np.pi, num=1000)
In [108]: data = pd.Series(0.1 * np.random.rand(1000) + 0.9 * np.sin(spacing))
In [109]: lag_plot(data);
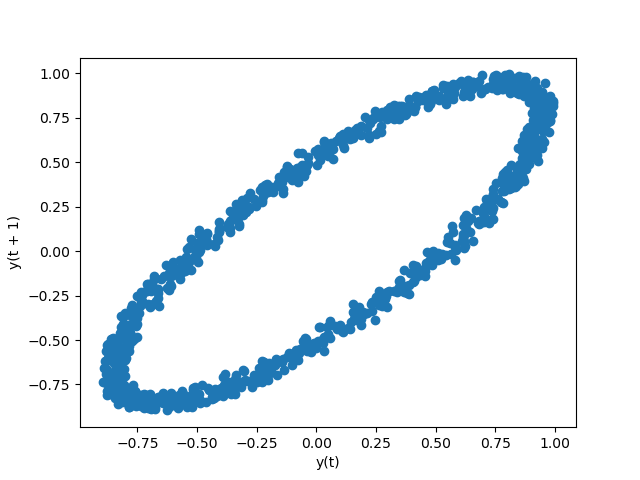
自相关图#
自相关图通常用于检查时间序列的随机性。这通过计算不同时间滞后数据值的自相关来实现。如果时间序列是随机的,则这些自相关对于任何和所有时间滞后分离都应接近零。如果时间序列是非随机的,则一个或多个自相关将显著非零。图中显示的水平线对应于 95% 和 99% 的置信区间。虚线是 99% 的置信区间。有关自相关图的更多信息,请参阅维基百科条目。
In [110]: from pandas.plotting import autocorrelation_plot
In [111]: plt.figure();
In [112]: spacing = np.linspace(-9 * np.pi, 9 * np.pi, num=1000)
In [113]: data = pd.Series(0.7 * np.random.rand(1000) + 0.3 * np.sin(spacing))
In [114]: autocorrelation_plot(data);
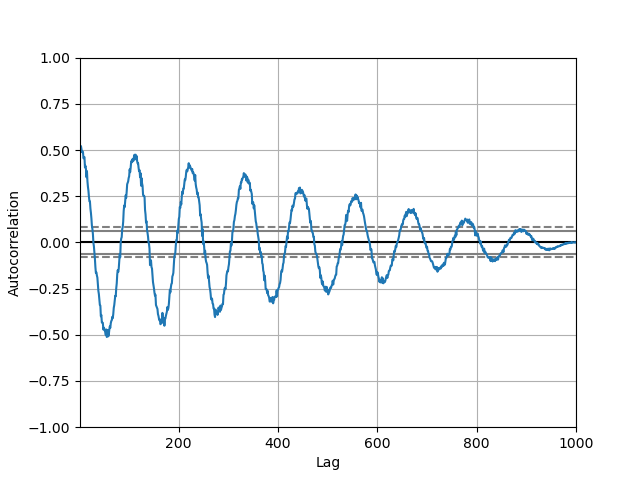
自助法图#
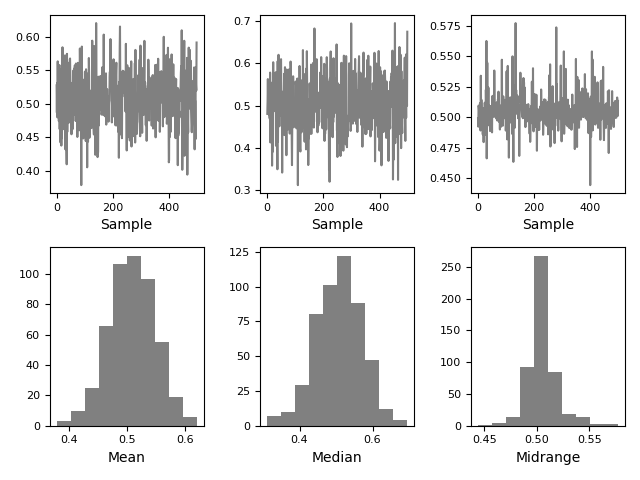
自助法图用于直观评估统计量的不确定性,例如均值、中位数、中域等。从数据集中选择指定大小的随机子集,计算该子集的统计量,并重复该过程指定次数。由此产生的图和直方图构成了自助法图。
In [115]: from pandas.plotting import bootstrap_plot
In [116]: data = pd.Series(np.random.rand(1000))
In [117]: bootstrap_plot(data, size=50, samples=500, color="grey");
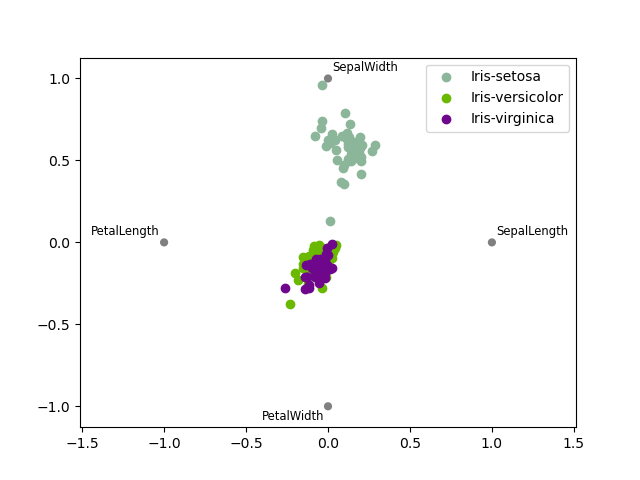
RadViz#
RadViz 是一种可视化多元数据的方法。它基于简单的弹簧张力最小化算法。基本上,您在平面上设置了一组点。在我们的例子中,它们均匀分布在单位圆上。每个点代表一个属性。然后您假设数据集中的每个样本都通过弹簧连接到这些点,弹簧的刚度与该属性的数值成比例(它们被归一化到单位区间)。我们的样本在平面上达到平衡的点(作用在我们样本上的力达到平衡的点)就是代表我们样本的点将被绘制的位置。根据样本所属的类别,它将以不同的颜色着色。有关更多信息,请参阅 R 包 Radviz。
注意:“Iris”数据集可在此处获取。
In [118]: from pandas.plotting import radviz
In [119]: data = pd.read_csv("data/iris.data")
In [120]: plt.figure();
In [121]: radviz(data, "Name");
绘图格式#
设置绘图样式#
从 1.5 版本及更高版本开始,Matplotlib 提供了一系列预配置的绘图样式。设置样式可以轻松地让图表呈现您想要的一般外观。设置样式就像在创建图表之前调用 matplotlib.style.use(my_plot_style) 一样简单。例如,您可以写入 matplotlib.style.use('ggplot') 以获得 ggplot 样式的图表。
您可以在 matplotlib.style.available 查看各种可用的样式名称,并且尝试它们非常容易。
通用绘图样式参数#
大多数绘图方法都有一组关键字参数,用于控制返回图表的布局和格式。
In [122]: plt.figure();
In [123]: ts.plot(style="k--", label="Series");
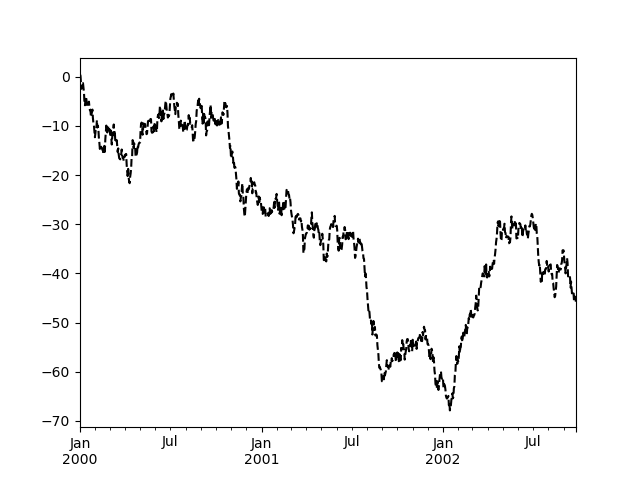
对于每种图表类型(例如 line、bar、scatter),任何附加的参数关键字都会传递给相应的 Matplotlib 函数(ax.plot()、ax.bar()、ax.scatter())。这些可以用于控制除了 pandas 提供之外的其他样式。
控制图例#
您可以将 legend 参数设置为 False 以隐藏图例,图例默认显示。
In [124]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [125]: df = df.cumsum()
In [126]: df.plot(legend=False);
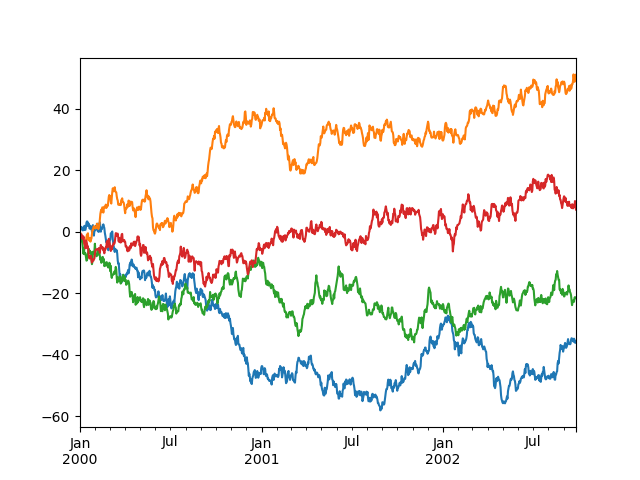
控制标签#
您可以设置 xlabel 和 ylabel 参数,为图表的 x 轴和 y 轴提供自定义标签。默认情况下,pandas 会将索引名称作为 xlabel,而 ylabel 留空。
In [127]: df.plot();
In [128]: df.plot(xlabel="new x", ylabel="new y");
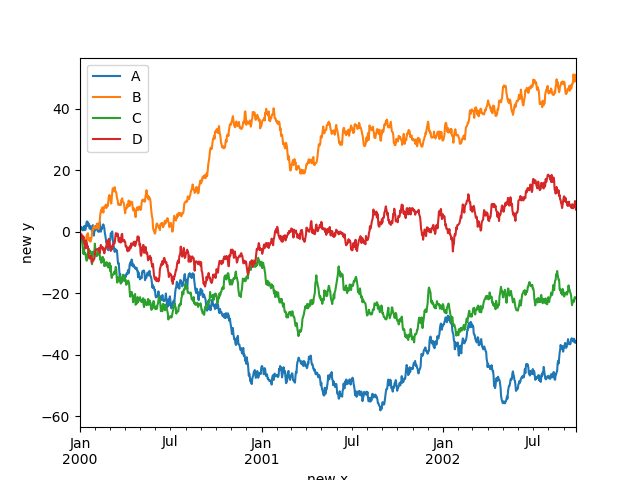
刻度#
您可以传递 logy 以获取对数刻度的 Y 轴。
In [129]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [130]: ts = np.exp(ts.cumsum())
In [131]: ts.plot(logy=True);
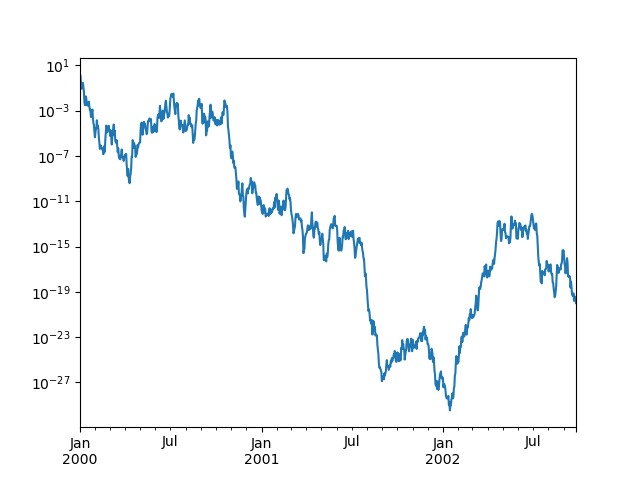
另请参阅 logx 和 loglog 关键字参数。
在辅助 Y 轴上绘图#
要在辅助 y 轴上绘制数据,请使用 secondary_y 关键字。
In [132]: df["A"].plot();
In [133]: df["B"].plot(secondary_y=True, style="g");
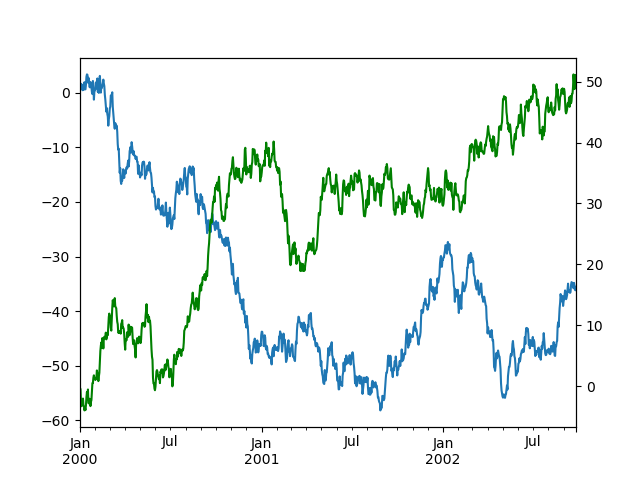
要绘制 DataFrame 中的某些列,请将列名提供给 secondary_y 关键字。
In [134]: plt.figure();
In [135]: ax = df.plot(secondary_y=["A", "B"])
In [136]: ax.set_ylabel("CD scale");
In [137]: ax.right_ax.set_ylabel("AB scale");
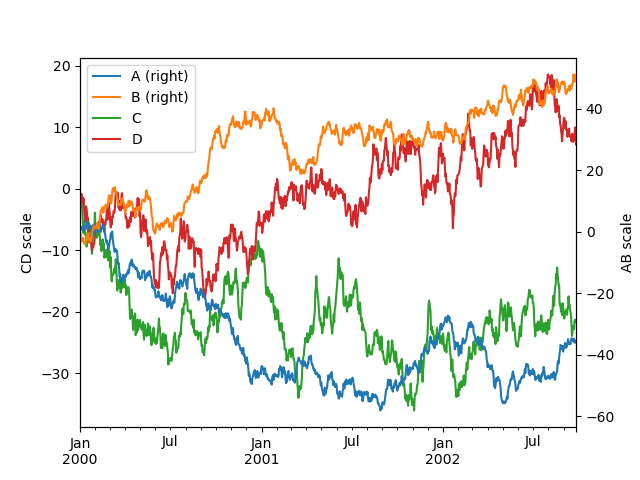
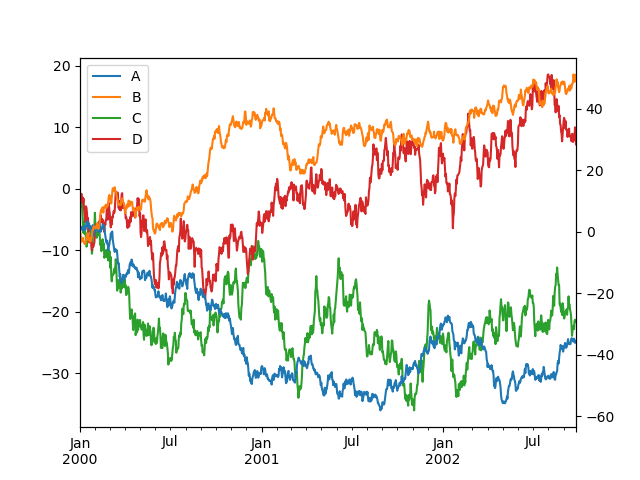
请注意,绘制在辅助 y 轴上的列在图例中会自动标记为“(right)”。要关闭自动标记,请使用 mark_right=False 关键字。
In [138]: plt.figure();
In [139]: df.plot(secondary_y=["A", "B"], mark_right=False);
时间序列图表的自定义格式化器#
pandas 为时间序列图表提供了自定义格式化器。这些格式化器改变了日期和时间轴标签的格式。默认情况下,自定义格式化器仅应用于由 pandas 使用 DataFrame.plot() 或 Series.plot() 创建的图表。要使它们应用于所有图表,包括 Matplotlib 创建的图表,请设置选项 pd.options.plotting.matplotlib.register_converters = True 或使用 pandas.plotting.register_matplotlib_converters()。
抑制刻度分辨率调整#
pandas 包含对常规频率时间序列数据的自动刻度分辨率调整。对于 pandas 无法推断频率信息的有限情况(例如,在外部创建的 twinx 中),您可以选择抑制此行为以用于对齐目的。
这是默认行为,请注意 x 轴刻度标签的执行方式:
In [140]: plt.figure();
In [141]: df["A"].plot();
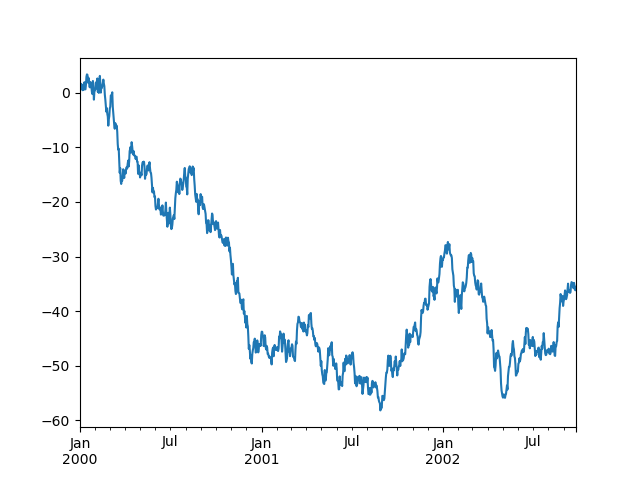
使用 x_compat 参数,您可以抑制此行为。
In [142]: plt.figure();
In [143]: df["A"].plot(x_compat=True);
如果您有多个需要抑制的图,则 pandas.plotting.plot_params 中的 use 方法可以在 with 语句中使用。
In [144]: plt.figure();
In [145]: with pd.plotting.plot_params.use("x_compat", True):
.....: df["A"].plot(color="r")
.....: df["B"].plot(color="g")
.....: df["C"].plot(color="b")
.....:
自动日期刻度调整#
TimedeltaIndex 现在使用原生 matplotlib 刻度定位器方法,对于刻度标签重叠的图,调用 matplotlib 的自动日期刻度调整功能很有用。
有关更多信息,请参阅 autofmt_xdate 方法和 matplotlib 文档。
子图#
DataFrame 中的每个 Series 都可以使用 subplots 关键字绘制在不同的轴上。
In [146]: df.plot(subplots=True, figsize=(6, 6));
使用布局并指定多个坐标轴#
子图的布局可以通过 layout 关键字指定。它可以接受 (rows, columns)。 layout 关键字也可以在 hist 和 boxplot 中使用。如果输入无效,将引发 ValueError。
由 layout 指定的行数 x 列数可容纳的轴数量必须大于所需子图的数量。如果布局可以容纳比所需更多的轴,则不绘制空白轴。与 NumPy 数组的 reshape 方法类似,您可以对一个维度使用 -1,以根据另一个维度自动计算所需的行数或列数。
In [147]: df.plot(subplots=True, layout=(2, 3), figsize=(6, 6), sharex=False);
上面的例子与使用以下代码相同:
In [148]: df.plot(subplots=True, layout=(2, -1), figsize=(6, 6), sharex=False);
所需的列数(3)是根据要绘制的序列数量和给定的行数(2)推断出来的。
您可以通过 ax 关键字将预先创建的多个轴作为列表传递。这允许更复杂的布局。传递的轴数量必须与要绘制的子图数量相同。
当通过 ax 关键字传递多个轴时,layout、sharex 和 sharey 关键字不影响输出。您应该显式传递 sharex=False 和 sharey=False,否则您将看到警告。
In [149]: fig, axes = plt.subplots(4, 4, figsize=(9, 9))
In [150]: plt.subplots_adjust(wspace=0.5, hspace=0.5)
In [151]: target1 = [axes[0][0], axes[1][1], axes[2][2], axes[3][3]]
In [152]: target2 = [axes[3][0], axes[2][1], axes[1][2], axes[0][3]]
In [153]: df.plot(subplots=True, ax=target1, legend=False, sharex=False, sharey=False);
In [154]: (-df).plot(subplots=True, ax=target2, legend=False, sharex=False, sharey=False);
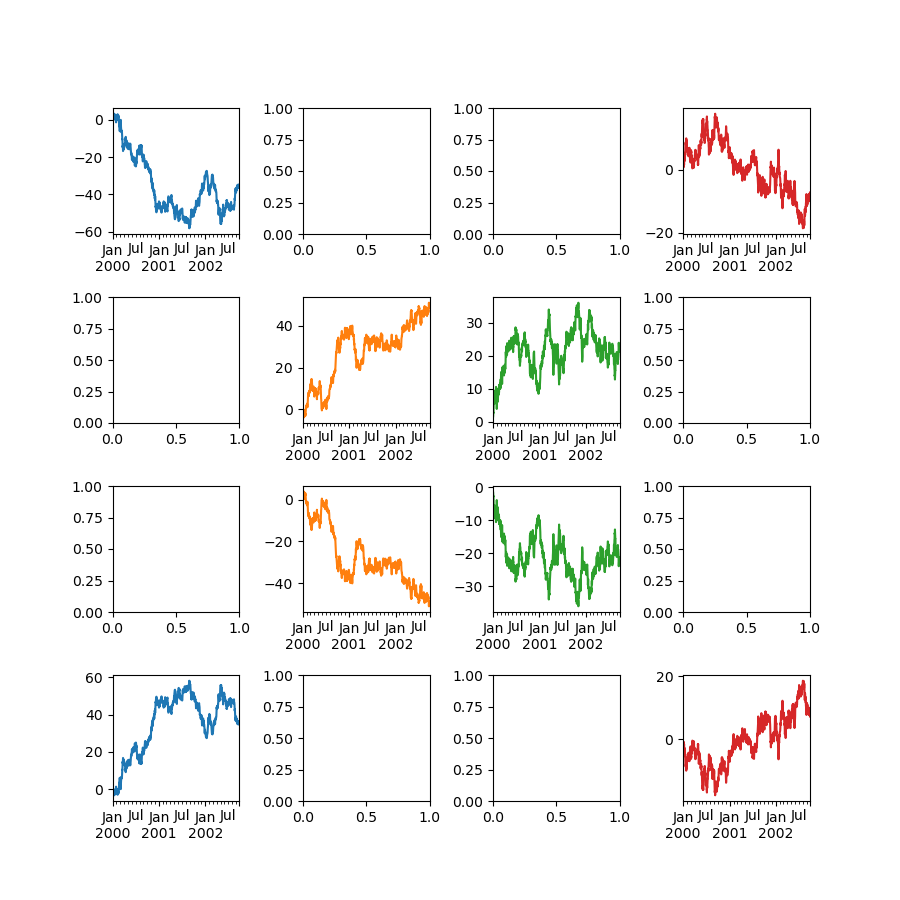
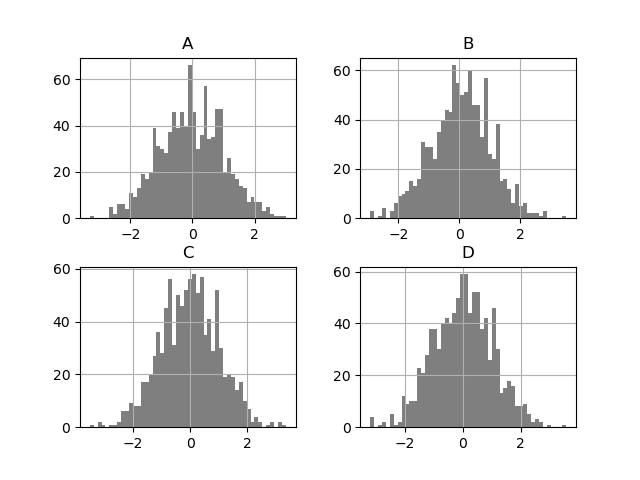
另一个选项是向 Series.plot() 传递 ax 参数,以在特定轴上绘图。
In [155]: np.random.seed(123456)
In [156]: ts = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
In [157]: ts = ts.cumsum()
In [158]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=list("ABCD"))
In [159]: df = df.cumsum()
In [160]: fig, axes = plt.subplots(nrows=2, ncols=2)
In [161]: plt.subplots_adjust(wspace=0.2, hspace=0.5)
In [162]: df["A"].plot(ax=axes[0, 0]);
In [163]: axes[0, 0].set_title("A");
In [164]: df["B"].plot(ax=axes[0, 1]);
In [165]: axes[0, 1].set_title("B");
In [166]: df["C"].plot(ax=axes[1, 0]);
In [167]: axes[1, 0].set_title("C");
In [168]: df["D"].plot(ax=axes[1, 1]);
In [169]: axes[1, 1].set_title("D");
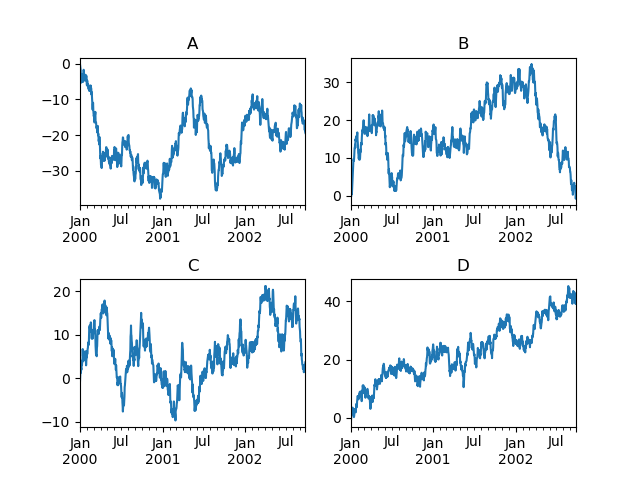
带误差棒的绘图#
DataFrame.plot() 和 Series.plot() 支持带误差棒的绘图。
水平和垂直误差棒可以通过 plot() 的 xerr 和 yerr 关键字参数提供。误差值可以通过多种格式指定:
作为
DataFrame或dict,其中包含与绘图DataFrame的columns属性匹配的列名,或与Series的name属性匹配。作为
str,表示绘图DataFrame的哪些列包含误差值。作为原始值(
list、tuple或np.ndarray)。必须与绘图DataFrame/Series的长度相同。
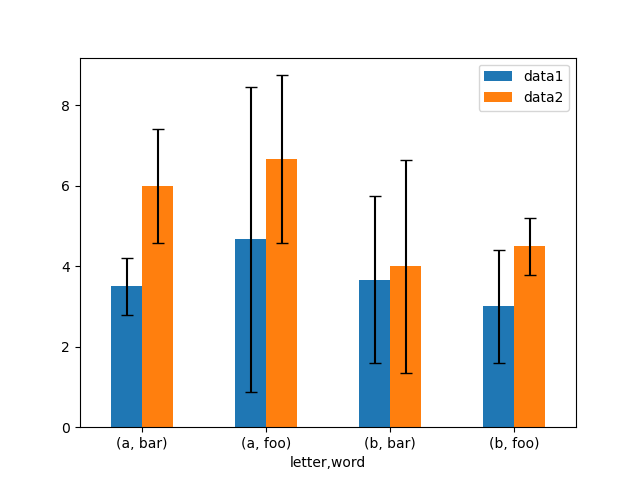
这是一个轻松绘制分组均值及其原始数据标准差的方法示例。
# Generate the data
In [170]: ix3 = pd.MultiIndex.from_arrays(
.....: [
.....: ["a", "a", "a", "a", "a", "b", "b", "b", "b", "b"],
.....: ["foo", "foo", "foo", "bar", "bar", "foo", "foo", "bar", "bar", "bar"],
.....: ],
.....: names=["letter", "word"],
.....: )
.....:
In [171]: df3 = pd.DataFrame(
.....: {
.....: "data1": [9, 3, 2, 4, 3, 2, 4, 6, 3, 2],
.....: "data2": [9, 6, 5, 7, 5, 4, 5, 6, 5, 1],
.....: },
.....: index=ix3,
.....: )
.....:
# Group by index labels and take the means and standard deviations
# for each group
In [172]: gp3 = df3.groupby(level=("letter", "word"))
In [173]: means = gp3.mean()
In [174]: errors = gp3.std()
In [175]: means
Out[175]:
data1 data2
letter word
a bar 3.500000 6.000000
foo 4.666667 6.666667
b bar 3.666667 4.000000
foo 3.000000 4.500000
In [176]: errors
Out[176]:
data1 data2
letter word
a bar 0.707107 1.414214
foo 3.785939 2.081666
b bar 2.081666 2.645751
foo 1.414214 0.707107
# Plot
In [177]: fig, ax = plt.subplots()
In [178]: means.plot.bar(yerr=errors, ax=ax, capsize=4, rot=0);
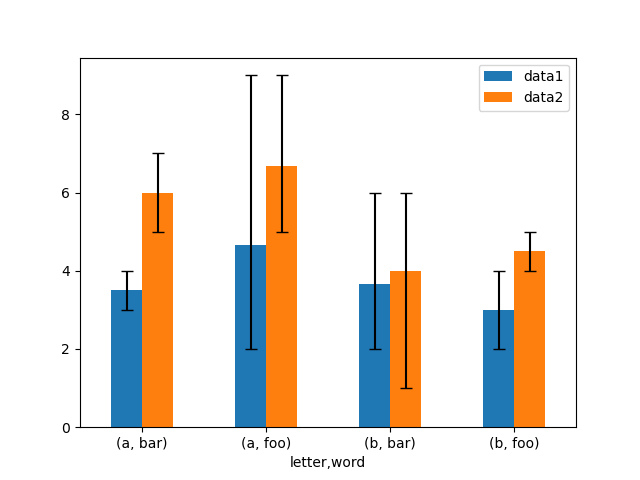
也支持不对称误差棒,但这种情况下必须提供原始误差值。对于长度为 N 的 Series,应提供一个 2xN 数组,表示下限和上限(或左和右)误差。对于 MxN 的 DataFrame,不对称误差应在一个 Mx2xN 数组中。
这是一个使用非对称误差棒绘制最小/最大范围的方法示例。
In [179]: mins = gp3.min()
In [180]: maxs = gp3.max()
# errors should be positive, and defined in the order of lower, upper
In [181]: errors = [[means[c] - mins[c], maxs[c] - means[c]] for c in df3.columns]
# Plot
In [182]: fig, ax = plt.subplots()
In [183]: means.plot.bar(yerr=errors, ax=ax, capsize=4, rot=0);
绘制表格#
DataFrame.plot() 和 Series.plot() 现在支持使用 Matplotlib 表格绘图,通过 table 关键字实现。table 关键字可以接受 bool、DataFrame 或 Series。绘制表格的简单方法是指定 table=True。数据将被转置以符合 Matplotlib 的默认布局。
In [184]: np.random.seed(123456)
In [185]: fig, ax = plt.subplots(1, 1, figsize=(7, 6.5))
In [186]: df = pd.DataFrame(np.random.rand(5, 3), columns=["a", "b", "c"])
In [187]: ax.xaxis.tick_top() # Display x-axis ticks on top.
In [188]: df.plot(table=True, ax=ax);
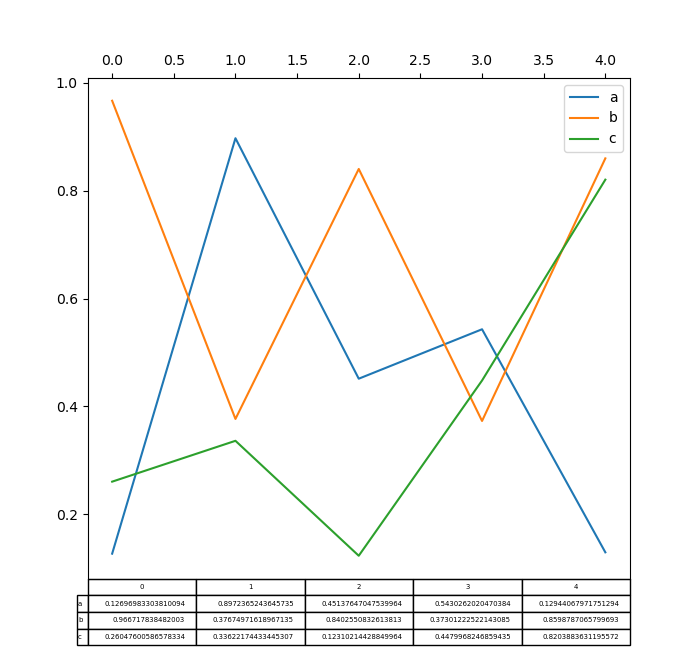
此外,您可以将不同的 DataFrame 或 Series 传递给 table 关键字。数据将按打印方法中显示的方式绘制(不自动转置)。如果需要,应手动转置,如下例所示。
In [189]: fig, ax = plt.subplots(1, 1, figsize=(7, 6.75))
In [190]: ax.xaxis.tick_top() # Display x-axis ticks on top.
In [191]: df.plot(table=np.round(df.T, 2), ax=ax);
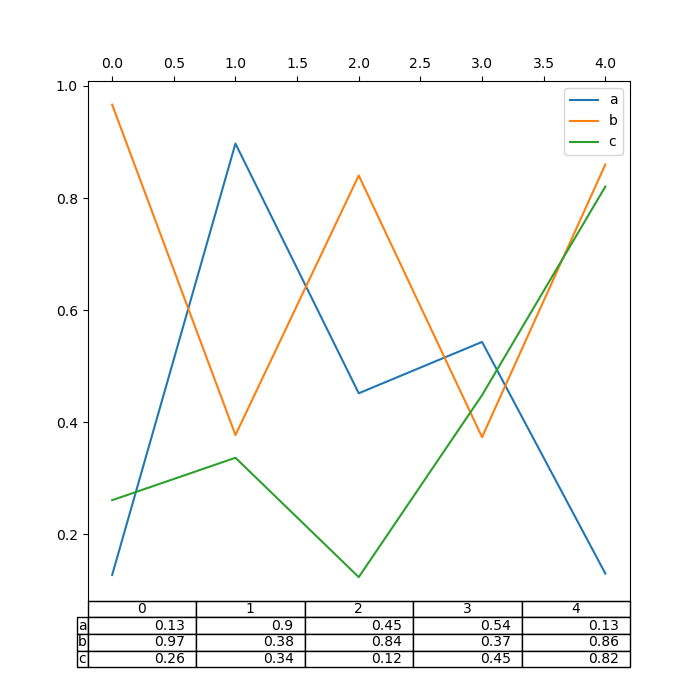
还存在一个辅助函数 pandas.plotting.table,它从 DataFrame 或 Series 创建表格,并将其添加到 matplotlib.Axes 实例中。此函数可以接受 Matplotlib table 具有的关键字。
In [192]: from pandas.plotting import table
In [193]: fig, ax = plt.subplots(1, 1)
In [194]: table(ax, np.round(df.describe(), 2), loc="upper right", colWidths=[0.2, 0.2, 0.2]);
In [195]: df.plot(ax=ax, ylim=(0, 2), legend=None);
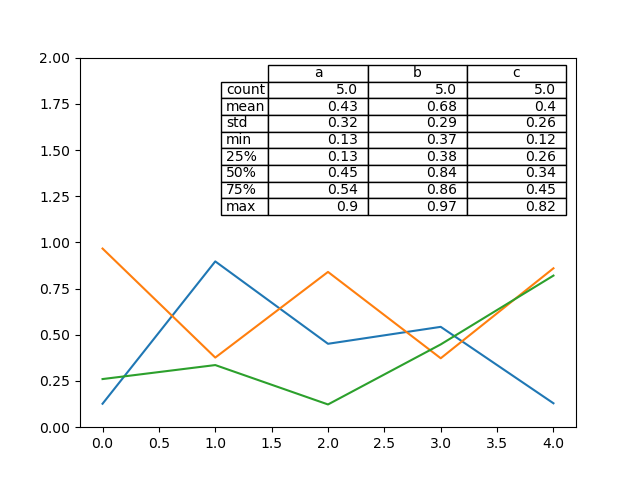
注意:您可以使用 axes.tables 属性获取轴上的表格实例,以便进行进一步的装饰。有关更多信息,请参阅 matplotlib 表格文档。
颜色映射#
绘制大量列时的一个潜在问题是,由于默认颜色的重复,可能难以区分某些序列。为了解决这个问题,DataFrame 绘图支持使用 colormap 参数,该参数接受 Matplotlib 颜色映射或注册到 Matplotlib 的颜色映射名称字符串。默认 Matplotlib 颜色映射的可视化可在此处获取。
由于 matplotlib 不直接支持基于线的图的颜色映射,因此颜色是根据 DataFrame 中列数确定的均匀间距选择的。没有考虑背景颜色,因此某些颜色映射会生成不易见的线条。
要使用 cubehelix 颜色映射,我们可以传递 colormap='cubehelix'。
In [196]: np.random.seed(123456)
In [197]: df = pd.DataFrame(np.random.randn(1000, 10), index=ts.index)
In [198]: df = df.cumsum()
In [199]: plt.figure();
In [200]: df.plot(colormap="cubehelix");
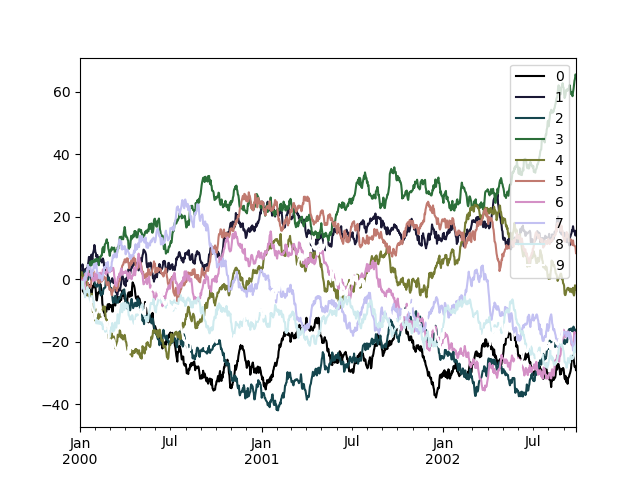
或者,我们可以直接传递颜色映射本身。
In [201]: from matplotlib import cm
In [202]: plt.figure();
In [203]: df.plot(colormap=cm.cubehelix);
颜色映射也可以用于其他图表类型,例如条形图。
In [204]: np.random.seed(123456)
In [205]: dd = pd.DataFrame(np.random.randn(10, 10)).map(abs)
In [206]: dd = dd.cumsum()
In [207]: plt.figure();
In [208]: dd.plot.bar(colormap="Greens");
平行坐标图
In [209]: plt.figure();
In [210]: parallel_coordinates(data, "Name", colormap="gist_rainbow");
安德鲁斯曲线图
In [211]: plt.figure();
In [212]: andrews_curves(data, "Name", colormap="winter");
直接使用 Matplotlib 绘图#
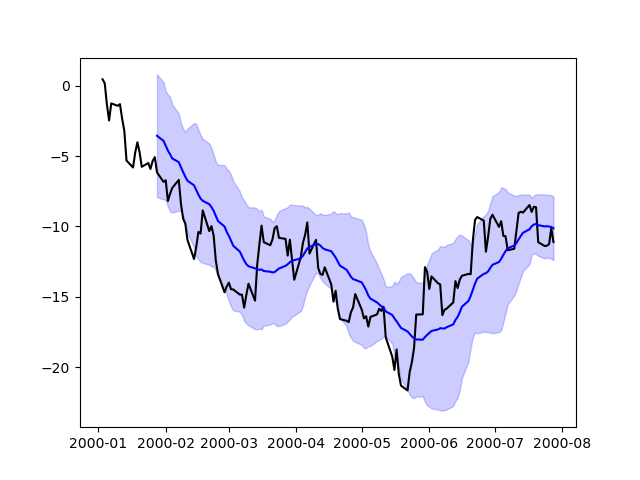
在某些情况下,直接使用 Matplotlib 准备图表可能仍然是更可取或必要的,例如当 pandas 尚不支持某种类型的图表或自定义时。Series 和 DataFrame 对象表现得像数组,因此可以直接传递给 Matplotlib 函数而无需显式转换。
pandas 还会自动注册识别日期索引的格式化程序和定位器,从而将日期和时间支持扩展到 Matplotlib 中几乎所有可用的绘图类型。尽管这种格式不提供与通过 pandas 绘图时相同的精细程度,但在绘制大量点时可能会更快。
In [213]: np.random.seed(123456)
In [214]: price = pd.Series(
.....: np.random.randn(150).cumsum(),
.....: index=pd.date_range("2000-1-1", periods=150, freq="B"),
.....: )
.....:
In [215]: ma = price.rolling(20).mean()
In [216]: mstd = price.rolling(20).std()
In [217]: plt.figure();
In [218]: plt.plot(price.index, price, "k");
In [219]: plt.plot(ma.index, ma, "b");
In [220]: plt.fill_between(mstd.index, ma - 2 * mstd, ma + 2 * mstd, color="b", alpha=0.2);
绘图后端#
pandas 可以通过第三方绘图后端进行扩展。主要思想是让用户选择不同于基于 Matplotlib 的默认绘图后端。
这可以通过在 plot 函数中将“backend.module”作为参数 backend 传递来实现。例如:
>>> Series([1, 2, 3]).plot(backend="backend.module")
或者,您也可以全局设置此选项,这样您就不需要在每次 plot 调用中指定关键字。例如:
>>> pd.set_option("plotting.backend", "backend.module")
>>> pd.Series([1, 2, 3]).plot()
或者
>>> pd.options.plotting.backend = "backend.module"
>>> pd.Series([1, 2, 3]).plot()
这或多或少等同于:
>>> import backend.module
>>> backend.module.plot(pd.Series([1, 2, 3]))
然后,后端模块可以使用其他可视化工具(Bokeh、Altair、hvplot 等)来生成图表。一些为 pandas 实现后端的库列在生态系统页面上。
开发者指南可在https://pandas.ac.cn/docs/dev/development/extending.html#plotting-backends 找到。