2019 年 pandas 用户调查
pandas 最近进行了一项用户调查,以帮助指导未来的开发。感谢所有参与者!本文介绍了主要结果。
您可以在 GitHub 上找到此分析和原始数据,并在 Binder 上运行
![]()
在 2019 年夏天进行调查的 15 天里,我们收到了大约 1250 份回复。
关于受访者
在 pandas 经验和使用频率方面有相当多的代表性,尽管大多数受访者经验更丰富。


我们包含了一些在 Python 开发者调查中也提出的问题,以便我们可以比较 pandas 用户与 Python 用户的群体。
90% 的受访者使用 Python 作为主要语言(PSF 调查中的比例为 84%)。
Yes 90.67%
No 9.33%
Name: Is Python your main language?, dtype: object
Windows 用户占比很高(请参阅 Steve Dower 关于此主题的演讲)。
Linux 61.57%
Windows 60.21%
MacOS 42.75%
Name: What Operating Systems do you use?, dtype: object
对于环境隔离,conda 是最受欢迎的。

大多数受访者只使用 Python 3。
3 92.39%
2 & 3 6.80%
2 0.81%
Name: Python 2 or 3?, dtype: object
pandas API
开源项目很难知道哪些功能是实际被使用的。我们问了一些问题来了解情况。
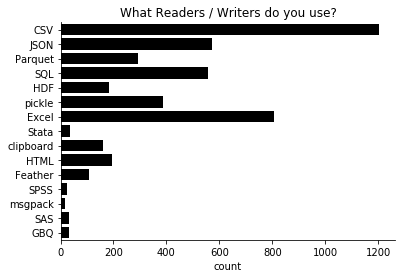
CSV 和 Excel 是(无论好坏)最流行的格式。
为了准备可能重构 pandas 内部结构,我们想了解拥有大量列(100 列或更多)的 DataFrame 的普遍程度。

pandas 正在缓慢增加新的扩展类型。Categoricals 是最受欢迎的,可空整数类型已经几乎和带时区的日期时间一样受欢迎。

更多更好的示例似乎是一个高优先级的开发项。pandas 最近获得了 NumFOCUS 资助,用于改进我们的文档,我们正利用这笔资金编写教程式文档,这应该有助于满足这一需求。

我们还询问了一些特定、常见的功能需求。
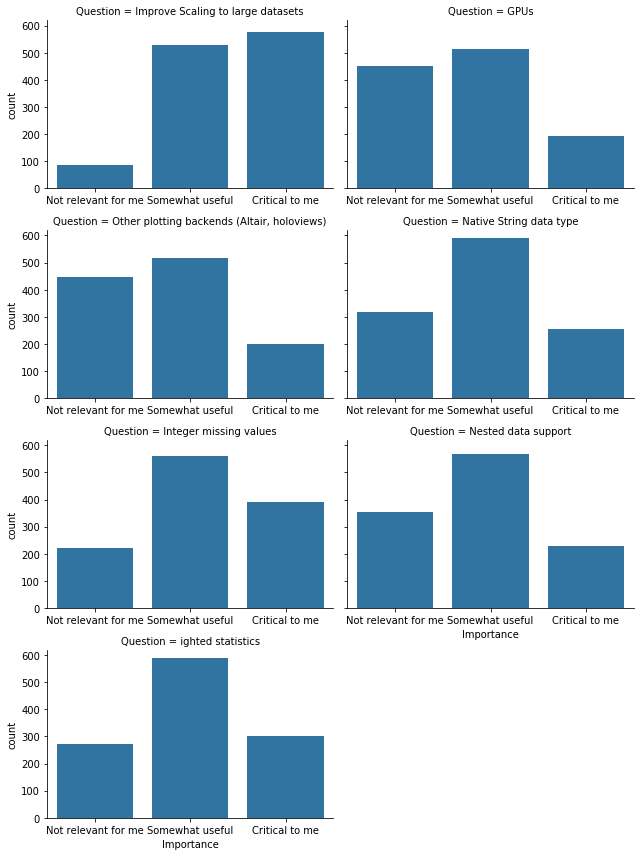
其中,最突出的明确需求是针对大型数据集的“扩缩”(scaling)。以下是一些观察结果:
- 也许 pandas 的文档应该更好地推广提供可伸缩 DataFrame 的库(例如 Dask, vaex, 和 modin)
- 内存效率(可能来自于原生字符串数据类型、更少的内部复制等)是一个有价值的目标。
之后,下一个最关键的改进是整数缺失值。这些实际上已在 Pandas 0.24 中添加,但它们不是默认设置,并且与 pandas API 的其余部分仍然存在一些不兼容性。
相较于 NumPy 等库,pandas 是一个不那么保守的库。我们正在接近 1.0 版本,在此过程中我们进行了许多弃用并做了一些彻底的 API 破坏性更改。幸运的是,大多数人对这种权衡感到满意。
Yes 94.89%
No 5.11%
Name: Is Pandas stable enough for you?, dtype: object
有一种看法(许多 pandas 维护者也持有这种看法)认为 pandas 的 API 过大。为了衡量这一点,我们询问用户是否认为 pandas 的 API 过大、过小或刚刚好。

最后,我们询问了对库的总体满意度,范围从 1 分(非常不满意)到 5 分(非常满意)。

大多数人非常满意。平均得分为 4.39 分。我期待随着时间的推移追踪这个数字。
如果您正在分析原始数据,请务必通过 @pandas_dev 与我们分享结果。